La mise en place du chiffrement/déchiffrement dans sylabe, l’implémentation de nebule en php, révèle quelques problèmes et spécificités de OpenSSL.
Lorsque il a fallu déchiffrer avec la commande openssl les objets chiffrés depuis sylabe, ça n’a pas marché.
Les objets chiffrés par sylabe, qui utilise openssl dans php, peuvent être déchiffrés par sylabe. Les objets chiffrés par nebule en bash, qui utilise la commande openssl, peuvent être déchiffrés via la même commande en bash. Le point commun est l’utilisation de la librairie openssl. Mais en pratique un objet chiffré dans sylabe que l’on essaye de déchiffrer avec la commande openssl (via nebule en bash) retourne une erreur ‘Bad Magic Number’. Et l’inverse ne marche pas non plus. Ah, c’est moche…
Salage
Le problème ici est lié à l’utilisation d’un ‘salage’ (salt). Cette valeur est générée aléatoirement par openssl pour complexifier le mot de passe de chiffrement et réduire les attaques par dictionnaire de mots de passe pré-hashés (rainbow-table). Le sel est une valeur publique contrairement au mot de passe, et doit impérativement être envoyé avec le fichier chiffré. Le salage est un renforcement de la procédure de chiffrement et non du mot de passe lui-même. Pour que le sel soit transmit avec les données chiffrées, openssl ajoute un petit entête aux données chiffrées avec notamment la valeur du sel. Il en résulte une petite augmentation de la taille du fichier des données chiffrées de 16octets. Or, la librairie openssl utilisée dans php ne génère pas de sel, les données chiffrées et non chiffrées ont la même taille.
Quelle solution apporter ?
Il est possible de gérer cet entête de fichiers chiffrés dans le code php. Cela entraîne une augmentation de la complexité du chiffrement/déchiffrement mais permet de conserver un comportement commun avec les objets actuellement générés en bash. Cette compatibilité ‘commune’ n’est pas universelle puisqu’elle n’est pas gérée par la librairie openssl dans php, et donc peut-être pas non plus dans d’autres environnements.
On peut aussi ne pas permettre d’utiliser un entête particulier et de gérer le salage de la même façon que l’IV. Cette solution casse la gestion des objets chiffrés actuels mais surtout complexifie les liens de chiffrement.
Une autre solution serait de ne pas utiliser le salage du tout. Une option de openssl le permet : -nosalt. Cela permet d’avoir un chiffrement plus simple et des objets chiffrés plus propres, et donc une implémentation plus universelle du chiffrement. On va cependant à l’encontre des recommandations faites par les développeurs de OpenSSL. Et on ré-ouvre potentiellement par dictionnaire pré-calculés.
Mais a-t-on vraiment besoin du salage ?
Le salage permet en fait de renforcer la sécurité de mots de passes potentiellement faibles ou à la limite de l’attaque par force brute.
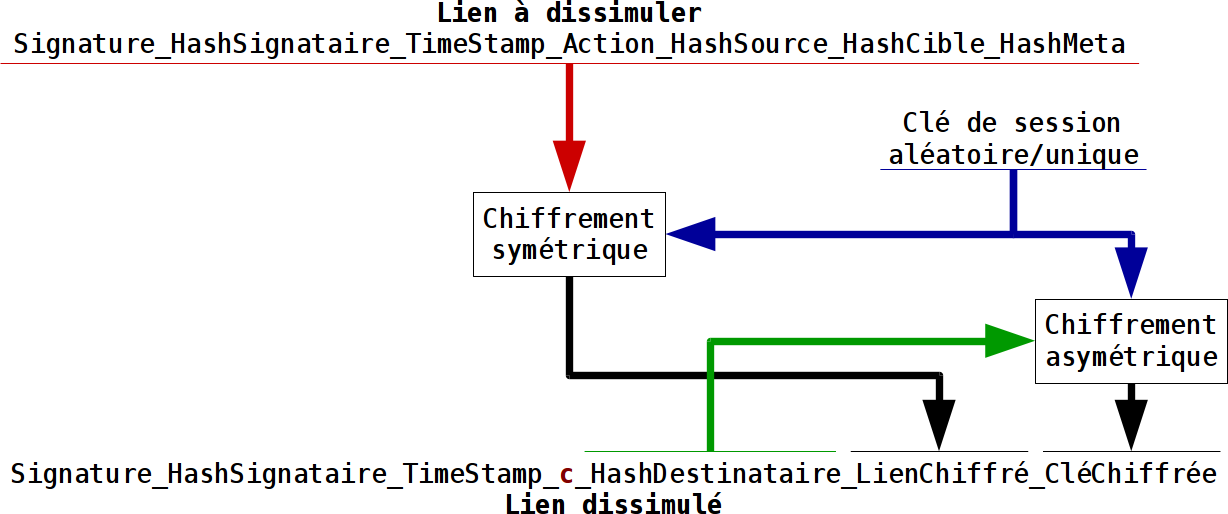
Le chiffrement des objets dans nebule impose l’utilisation d’une clé de session aléatoire. Si l’espace des valeurs des clés de sessions est aléatoire et suffisamment grand, une attaque par dictionnaire est impossible. C’est impossible parce qu’il est dans ce cas précis impossible de pré-calculer et encore moins de stocker dans un dictionnaire l’intégralité des valeurs possibles. Un espace des valeurs de clé suffisamment grand peut se comprendre par une entropie correspondant à 128bits et plus.
Le script bash référence de nebule génère actuellement une clé de session de 64octets de valeurs hexadécimales, soit 256bits d’entropie réelle. Le code php de sylabe génère actuellement une clé de session de 128octets aléatoires, soit 1024bits d’entropie réelle.
Donc, le salage va être volontairement supprimé dans le chiffrement des objets tel que mis en place dans nebule.
Semence
Un problème similaire existe avec l’IV (Initial Vector, vecteur initial ou semence).
Lorsque l’on réalise un chiffrement symétrique, celui-ci se fait typiquement par blocs de données. Ce découpage peut entrer en interférence, en quelque sorte, avec les données à chiffrer. Si ces données sont répétitives suivant la taille du bloc ou un multiple, alors les blocs de données chiffrées correspondantes vont être identiques. Et cette répétition est détectable et fourni des informations sur le contenu non chiffré…
Pour remédier à ce problème, il existe différentes méthode d’organisation du chiffrement (pour le même algorithme de chiffrement) que l’on appelle modes d’opération. Certains modes introduisent un chaînage entre des blocs contiguës pour camoufler les données répétitives. D’autres modes mettent en place d’un compteur par bloc qui sera combiné avec les données pour forcer un peu de variabilité entres blocs répétitifs.
Il reste cependant à traiter le premier bloc. Pour cela on utilise l’IV qui est soit la première valeur pour le chaînage soit la première valeur du compteur en fonction du mode d’opération. Parce que sinon ce premier bloc, chiffré avec le même mot de passe, donnera le même bloc chiffré et donc trahira un début de données identique entre plusieurs fichiers chiffrés. L’IV est une valeur publique contrairement au mot de passe, et doit impérativement être envoyé avec le fichier chiffré.
Mais a-t-on vraiment besoin de cet IV ?
Comme dans le cas du salage, l’utilisation de d’une clé de session aléatoire et différente pour chaque objet fait que, même pour un contenu identique dans les premiers blocs, cela donnera des blocs chiffrés différents.
Donc, le vecteur initial va être volontairement supprimé dans le chiffrement des objets tel que mis en place dans nebule.
Premier problème suite à ça, l’instruction en php openssl_encrypt nécessite un paramètre IV non nul…