Échanges
La grande majorité des Systèmes d’Information (SI) reposent aujourd’hui :
- sur la notion de données, d’applications et de traitement local ;
- sur la notion de serveur sur le réseau, une grosse machine qui centralise et traite les données au profit des utilisateurs.
Il y a aujourd’hui un mouvement de déplacement des données du stockage local vers des points de stockages distants, des serveurs sur le réseau. Le traitement se faisant toujours au plus proche des données, il suit le même mouvement de convergence. Le concept du nuage (Cloud computing) est le plus récent raffinement de la technologie client-serveur. Ce mouvement de convergence vers l’internet a au moins un bénéfice, il rend nos données omniprésentes. Elles sont ainsi en permanence accessibles quel que soit l’endroit où on se trouve. Mais, plus la distance entre nous et nos données est grande, plus les possibilités d’utilisations sont limitées et plus le contrôle est difficile. Il faut désormais s’identifier pour accéder à nos données !
Une donnée que l’on transmet à autrui, c’est une donnée sur laquelle on perd irrémédiablement tout contrôle.
On avait oublié qu’un serveur, en pratique, ce peut être tout le monde. Le pair à pair (P2P – Peer to Peer) nous démontre que cela marche, et même que cela marche très bien. IPv6 est fait pour permettre à tout le monde d’avoir une adresse sur l’Internet, d’être directement visible. Nous pouvons à tout instant être à la fois consommateur et hébergeur de nos propres données.
Alors, avons nous vraiment besoin des serveurs centralisés pour être présent sur Internet ?
![]()
Risques
Lorsque l’on échange de l’information, on prend des risques. Ces risques sont similaires pour les machines sur les réseaux numériques comme pour les humains dans leurs rapports sociaux.
Ces risques sont :
- de divulguer des informations confidentielles ou privées à d’autres ;
- d’être trompé sur la véracité ou la finalité des informations que l’on reçoit des autres.
Les conséquences d’une manipulation de l’information peuvent être au mieux bénignes, ou létales dans le pire des cas.
Mais a-t-on vraiment le choix ? Jusqu’où peut-on faire confiance à autrui ?
La confiance est un risque que l’on calcule. Ce calcul dépend de l’information échangée, des interlocuteurs, de l’environnement et du gain attendu.
L’être humain est un assemblage biologique complexe. Comme tout être vivant, il est parfaitement adapté à son environnement, à la fois hostile et bienfaiteur. Il est aussi profondément social. Ses relations à ses semblables lui sont vitales. Il sait naturellement, mieux que les machines, estimer le risque si on lui présente les bonnes informations.
Les systèmes d’information sont des démultiplicateurs du traitement de l’information au profit des humains. L’outil informatique doit être neutre et complet mais synthétique dans la présentation des informations nécessaires à la gestion du risque. Il doit aussi assurer autant que possible la sûreté de son fonctionnement propre et protéger l’utilisateur de la corruption de données.
Jusqu’à quel point la machine peut assister l’être humain dans sa gestion du risque ? Jusqu’à quel point la machine peut prendre l’initiative dans la protection de l’être humain ?
![]()
Informations
Mais au fait, que manipule-t-on dans nos systèmes d’information ? De l’information ?
Non, des données!
Une information décrit l’état ou la modification de l’état d’un objet, d’un sujet.
Une donnée est une représentation numérique de l’information. Une information numérisée de la même façon en différents lieux, par différentes personnes ou en différentes époques génère la même donnée. Ainsi, l’information comme la donnée ont des formes parfaitement délimitées, impersonnelles et atemporelles. Et l’information n’ayant par essence par d’attache ou de propriétaire, il en est de même pour la donnée qui en est dérivée.
Il est possible d’identifier chaque donnée ou agrégat de données. La mauvaise méthode, ce que l’on fait aujourd’hui presque partout, c’est de repérer les données par un chemin et un nom, par une Uniform Resource Locator (URL). C’est d’autant plus une mauvaise méthode si, derrière une URL, la donnée n’est pas constante dans le temps. Une Uniform Resource Identifier (URI) est bien plus fiable et universelle.
La fonction de hachage ou prise d’empreinte est la seule façon de générer une URI à la fois universelle et statistiquement unique. Elle est parfaitement reproductible et unique pour une seule et même donnée numérique. Elle est de plus non falsifiable si elle est cryptographique.
Dans nebule, les données sont identifiées strictement et uniquement par leurs empreintes à l’aide de fonctions de hachage cryptographiques.
Par exemple, le texte du paragraphe précédent en gras, encodé en UTF-8, est identifié par l’empreinte en SHA-256 :
dcaca243dca11e2286a29525c0f5500c5d84c86452490642eaa65a9afa1d872d
Le niveau de sécurité attendu est en fait de 2128, soit tout de même la probabilité pour avoir deux données avec la même empreinte de 1 chance sur 1,1579×1077.
La fonction de prise d’empreinte n’est pas imposée parce qu’elle changera forcément dans le temps, et d’un pays à l’autre. Cependant, elle doit générer un identifiant universel, atemporel, univoque et infalsifiable des données. La valeur de l’empreinte est représentée en hexadécimal. Il est conseillé de travailler avec des empreintes de 256bits au minimum.
![]()
Gestion
Nous savons maintenant ranger les données sous forme d’objets. Accumuler des objets, c’est bien, mais ça a autant de valeur que d’accumuler de l’argent, ça ne sert pas à grand chose en soi. La vraie valeur, c’est l’usage que l’on en fait. L’usage des données, c’est le traitement de l’information qu’elles contiennent. Et ça tombe bien, les ordinateurs, éléments de base de nos systèmes d’information, sont spécialisés dans le traitement des données.
Comme dans les relations sociales entre humains, et d’une façon générale pour toutes les espèces vivantes, l’échange d’information nécessite sa mise en forme dans un langage. Dans le monde numérique, ces langages sont des protocoles de communication. Il en existe une multitude. Certains protocoles sont érigés au rang de norme universelle. Mais même les normes sont bafouées si l’intérêt est autre.
Dans nebule, les liens sont l’expression d’un protocole d’échange, c’est à dire un langage. Ce langage va permettre de gérer l’usage des objets :
- La caractérisation d’un objet et implicitement son utilisation.
- Le groupement et l’indexation des objets.
- La différenciation et l’évolution temporelle d’un objet.
- La facilité de partage ou au contraire la protection d’un objet.
Un lien se matérialise par ce que l’on appelle le registre de lien. Ce n’est pas un objet par lui-même. Le coeur du registre est constitué d’un triplet (au sens RDF). Il peut tout à fait être assimilé à une phrase avec un sujet, un complément et un verbe :
Sujet_Complément_Verbe
Cet arrangement du registre, cette grammaire, n’est pas tout à fait celui du RDF mais c’est le plus simple. On peut lier un sujet et un complément sans nécessiter de verbe, c’est à dire sans action. On peut même considérer un lien ne contenant que le sujet.
Comme nous souhaitons lier des objets mais sans manipuler leur contenu souvent volumineux, le registre fait référence à l’objet source, l’objet destinataire et le méta-objet à la place du sujet, complément et verbe. Naturellement, la référence d’un objet c’est une URI : son empreinte. Cela nous donne la base du registre de la forme :
ObjetSource_ObjetDestination_MétaObjet
Exemple :
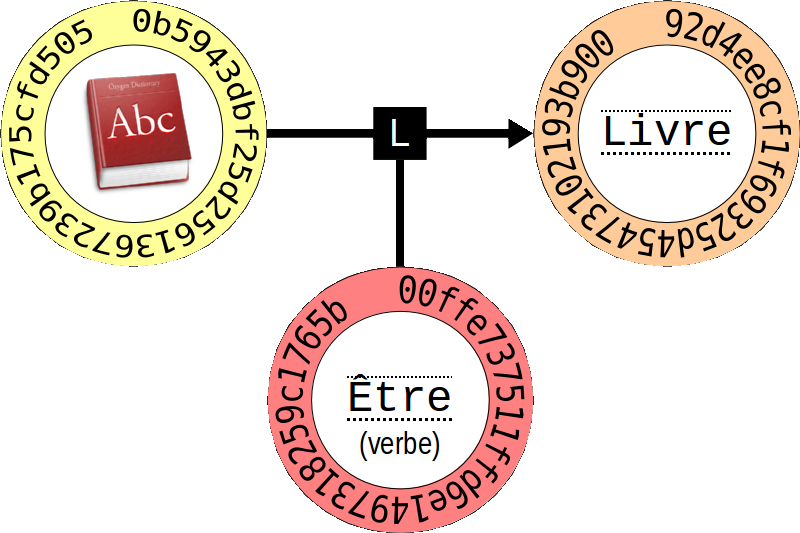
Le lien L ici représenté relie l’objet du livre à l’objet du mot Livre avec le sens de l’objet du verbe être. Il peut s’exprimer simplement par : « Ceci est un livre« .
Ce lien se traduit par le registre :
0b5943dbf25d2561367239b175cfd505_92d4ee8cf1f69325d45473102193b900_00ffe737511ffd6e1497318259c1765b
La gestion des liens nécessite que l’on décrive ce que l’on fait de ces liens. C’est par exemple une action de création du lien ou de sa suppression.
Le lien est une information à part entière, donc il est par nature atemporel. D’un autre point de vue, logiquement, il ne peut y avoir suppression que si il y a eu précédemment création. Ce n’est pas le triplet qui nécessite un repérage dans le temps, mais l’action sur celui-ci. Le registre de lien s’agrandit donc pour intégrer une trace temporelle et une action :
Date_Action_ObjetSource_ObjetDestination_MétaObjet
L’être humain n’est pas numérisé. Il dispose d’une interface (un programme) pour manipuler ses données. Il doit disposer lui aussi d’un identifiant pour qu’il soit reconnu en tant qu’individu, comme une empreinte. On retrouve souvent un identifiant sous forme d’une adresse électronique ou d’un condensé du prénom et du nom. Cet identifiant est par nature une valeur publique puisqu’il est transmis aux autres êtres humains.
Cependant il doit être associé à une valeur privée pour empêcher votre voisin de s’identifier à votre place. C’est généralement un mot de passe. Il est indispensable que cette valeur privée soit secrète pour que l’identifiant public ait de la valeur. Son équivalent social s’appelle la vie privée.
Il existe un système numérique qui permet de manipuler deux valeurs fortement associées : une clé publique et une clé privée. C’est ce que l’on appelle la cryptographie asymétrique. La clé privée est protégée par un mot de passe ou protégée dans un composant électronique sécurisé. Cette clé privée permet notamment de générer des signatures numériques infalsifiables.
La clé publique est la valeur qui permet à tout individu de vérifier l’identité d’un individu en particulier, celui qui détient la clé privée associée. Dans nebule, la clé publique sert d’identifiant. Et mieux encore, reconnue par son empreinte, elle peut être elle-même manipulée comme un simple objet. La gestion des identités devient une simple gestion d’objets.
Un individu est reconnu dans nebule sous le terme d’entité.
Pour que la provenance du lien soit établie sans ambiguïté, il faut ajouter au registre de lien l’identifiant du créateur et une signature. Voici la forme complète du registre de lien :
Signature_Entité_Date_Action_ObjetSource_ObjetDestination_MétaObjet
Dans nebule, le lien permet d’organiser directement les données. Il permet d’adapter ces données à tous les moyens et formes d’échanges actuellement utilisés.
La gestion des objets par les liens ouvre plein de nouvelles opportunités. Les objets deviennent incorruptibles et peuvent être répartis tout autour du monde. Les entités sont gérées comme des objets, les programmes aussi. Les entités comme les programmes deviennent globaux. Les liens sont permanents et restent valables et vérifiables même sur des ordinateurs isolés de l’Internet.
La gestion des données est faite à l’échelle locale, celle de l’individu et de son environnement social proche. Mais la validité des données est globale.
La fonction de cryptographie asymétrique et la fonction de prise d’empreinte ne sont pas imposées parce qu’elles changeront forcément dans le temps, et d’un pays à l’autre.
![]()
Conclusion
Le projet nebule propose une façon radicalement différente de gérer nos données et de penser nos systèmes d’information. Il se concentre sur la donnée plutôt que sur les machines qui l’exploitent. Les réseaux et les serveurs perdent de l’importance au profit des données qu’ils hébergent. L’ensemble repose sur trois principes :
- L’objet : il représente la face interne, la donnée. C’est la brique de base du monde numérique comme l’atome pour l’univers.
- Le lien : il représente la face externe, les échanges de données. Ils rapprochent ou repoussent les objets entre eux comme la gravitation dans l’univers.
- La confiance : c’est la solidité de l’ensemble, la garantie qu’un petit dieu local ne viendra modifier ni les atomes ni leurs liaisons à son profit.
Ces principes sont traduits en dix règles de mise en application :
- Identifier strictement les objets par des empreintes. Comme les objets physiques, les données doivent être parfaitement identifiables et discernables. Il ne doit pas être possible de modifier un objet. Seule une empreinte cryptographique permet de nous assurer de la cohérence d’un objet. Le projet nebule utilise aujourd’hui l’algorithme SHA256 afin d’identifier tous les objets numériques. Tout objet modifié devient soit invalide soit un nouvel objet à part entière. (
In) - Chiffrer les objets au besoin. Si le besoin s’en fait sentir, un objet peut être chiffré. Il devient ainsi un nouvel objet dérivé dont les données sont cachées. Le déchiffrement de cet objet dérivé permet de régénérer l’objet d’origine. L’objet d’origine restauré peut être vérifié par son empreinte. (
Co) - Lier les objets entre eux. Les objets sont partagés par un mécanisme de liens. Le lien est l’élément central des communications. Chaque lien relie trois objets et est marqué d’une date, d’une action et d’une signature. Les trois objets sont exclusivement référencés dans un lien par leurs empreintes. Ces empreintes d’objets sont représentées dans l’ordre sujet-complément-verbe, c’est à dire l’objet sujet du lien, un objet (complément) contenant par exemple une propriété, et un objet (verbe) décrivant la relation entre le sujet et le complément.
- Signer tous les liens. Une signature vient verrouiller chaque lien. Le même lien peut être créé par plusieurs entités, seule la partie signature change. La signature est une valeur cryptographique calculée avec l’empreinte complète du lien et la clé privée de l’entité signataire. (
In) (Au) (Re) (Im) - Valider les objets par les liens et leurs signatures. Les objets ne sont pas signés directement, seule leur empreinte cryptographique les distingue. Intégrer l’empreinte d’un objet dans un lien, quel qu’en soit la position, c’est reconnaître et valider implicitement cet objet. Cela équivaut à une signature de l’objet. (
In) - Gérer les création/suppression de liens avec horodatage. Chaque lien intègre une action et est daté afin d’être repéré dans le temps. Il existe plusieurs types de liens. Une fois créés, les liens sont définitifs, mais un type de lien permet une désactivation de liens sans nécessiter de suppression. Les créations et désactivations de liens sont propagées de la même façon.
- Caractériser les entités par des bi-clés cryptographiques. Une entité, quelle soit de type humaines ou robotiques, dispose de deux actions dites fortes. La première action forte est le chiffrement d’objets avec sa propre clé publique ou les clés publiques d’autres entités. La deuxième action forte est la signature de liens avec sa propre clé privée. Des actions comme la génération d’objets et de liens sont des actions dites faibles. Une entité peut ainsi être caractérisée par sa clé publique et/ou sa clé privée. Ces deux clés étant intimement liées, on peut considérer que la clé publique est suffisante pour caractériser une entité. (
Au) (Im) - Gérer les entités comme des objets. Les entités sont caractérisées par deux clés cryptographiques. Ces deux clés doivent être stockées comme toutes autres données, elles sont donc des objets comme les autres. Elles sont ainsi diffusées de la même façon que des objets avec le même mécanisme de liens. (
In) (Di) - Permettre la génération et la diffusion d’objets avec ou sans connexion réseau. La génération et le stockage d’objets et de liens sont complètement indépendants du réseau. Leur transmission nécessite une connexion réseau ou un support amovible. Le réseau est un support de transport mais il n’est ni exclusif ni obligatoire. (
Di) - Aucun objet ou lien n’est transmis, tout échange se fait par téléchargement. Une entité ne peut rien envoyer à une autre entité. Si elle veut lui transmettre un objet, elle doit le mettre à disposition et le lier à l’autre entité. Cette façon d’échanger réduit les risques de messages non sollicités. Au besoin, une entité annuaire peut aussi permettre la transmission d’objets entre entités qui ne se connaissent pas.
Légende : confidentialité (Co), intégrité (In), disponibilité (Di), authentification (Au), imputabilité (Im) et non répudiation (Re).
La documentation technique de référence de nebule se trouve ici. La version actuelle du protocole est la v1.3.
Visitez :
introduction
les actualités (blog)
la documentation
à propos
::
(création 2013 – màj 2019)
4 réflexions au sujet de « Description »