De la même façon que l’on a implémenté des entités de recouvrement pour récupérer les objets protégés, il serait peut-être utile de pouvoir mettre en place des entités de recouvrement des liens dissimulés.
Catégorie : anonymisation
Billets et entité
La réflexion continue autour d’une implémentation d’une monnaie virtuelle.
L’idée que le billet électronique est une entité, donc un bi-clé cryptographique, est intéressante à étudier. Cela permet de le rendre autonome mais il faut dans ce cas considérer que sa clé privée devient publique ou connue de plusieurs autres entités, ce qui revient au même. On ne peut donc pas supprimer la nécessité de gérer la confiance via un tier de confiance ou une chaîne de blocs pour consolider le graphe des transactions.
Mais si ce billet électronique est constitué de la chaîne des entités du billets, alors on a un mécanisme d’anonymisation.
Anonymisation des fichiers transcodés
Suite aux articles Anonymisation/dissimulation des liens – ségrégation partielle, transcodage et Transcodage des liens dissimulés, il apparaît un problème avec le contenu des fichiers transcodés.
Le fait qu’une entité synchronise des liens dissimulés que d’autres entités partagent et les range dans des fichiers transcodés peut révéler l’ID de l’objet transcodé. Et par tâtonnement on peut retourner ainsi le transcodage de tous les objets.
Il suffit qu’une entité attaquante génère un lien dissimulé à destination d’une entité attaquée concernant un objet en particulier. L’entité attaquée va alors ranger le lien dissimulé dans le fichier transcodé. L’entité attaquante peut alors rechercher quel fichier transcodé contient sont lien dissimulé et en déduire que ce fichier transcodé correspond à l’objet.
En plus, si le lien dissimulé n’a aucune action valable, il ne sera pas exploité, donc pas détecté par l’entité attaquée.
Il faut trouver une parade. Peut-être que l’on peut chiffrer les fichiers transcodé avec la clé de transcodage. A voir…
L’algorithme de transcodage doit être non réversible.
Anonymisation/dissimulation des liens – transcodage
Suite à l’article Anonymisation/dissimulation des liens – ségrégation et temporalité et ségrégation partielle, la réflexion et l’implémentation sur le stockage et l’échange des liens dissimulés progresse.
La méthode de ségrégation des liens dissimulés développée est suffisante pour retrouver les liens dissimulés et les partager. Mais si le partage est efficace parce que l’on ne récupère que les liens dissimulés des entités connues, la lecture des liens n’est clairement pas efficace.
Lors de la consultation des liens d’une objet particulier, il faut lire tous les liens de l’objet, facile, et lire l’intégralité des liens dissimulés parce que l’on ne sait pas à l’avance quelle entité à dissimulé des liens pour cet objet. Il manque de pouvoir localement (indépendamment du partage) stocker les liens en fonction des objets source, cible et méta. Mais il faut aussi ne pas dévoiler cette association d’objets cités dans la partie dissimulée du lien, ce qui permet rapidement de lever la partie dissimulée.
Il est possible de transcoder les identifiants des objets cités par le lien dissimulé. On parle bien de travailler toujours sur des fichiers de stockage dédiés aux liens dissimulés, et donc indépendamment des liens non dissimulés. Ce transcodage doit permettre de ne pas révéler l’association entre les objets cités par le lien dissimulé. Ce transcodage peut être commun à tous les objets avec une clé de codage commune, ou chaque objet peut disposer de sa propre clé de codage. Et bien sür, chaque entité dispose de sa/ses clés de transcodage, donc chiffrées avec la clé privée.
Un transcodage avec une clé unique est plus facile puisque l’on peut chiffrer cette clé et la stocker à un endroit unique, mais il est moins sür que le transcodage à clés individuelles.
Pour commencer on va partir sur la base de la clé unique de transcodage.
Les liens dissimulés dans des fichiers transcodés sont lisibles publiquement et peuvent potentiellement être synchronisés mais ils n’ont pas vocation à remplacer les liens dissimulés dans les fichiers dédiés à la ségrégation et utilisés lors du partage des liens.
Le nettoyage des fichiers des liens dissimulés et transcodés devient un nouveau problème.
Plusieurs entités pouvant localement générer des liens dissimulés, et donc utiliser des clés de transcodage différentes, il n’y a pas de méthode de nettoyage générique des liens dissimulés dans les fichiers transcodés. Seule une entité peut faire le nettoyage de ses propres fichiers transcodés. Il faut donc que ces fichiers transcodés soient clairement associés à une entité.
Il est possible par contre de supprimer tous les fichiers transcodés d’une entité (ou plus). Il faut dans ce cas que l’entité, une fois déverrouillée, reconstitue ses fichiers transcodés.
Cela lève un nouveau problème, comment savoir que tous les fichiers transcodés sont présents et qu’ils sont à jour. Avec cette méthode, il ne faut pas que les fichiers dédiés à la ségrégation des liens dissimulés pour une entité soient manipulés par une autre entité parce que les fichiers transcodés ne seront pas synchrones. Et les transferts ne sont pas possibles.
Les entités ne doivent pas synchroniser les liens dissimulés des autres entités !
Il reste encore des réflexions à mener autour de cette méthode de transcodage.
Double offuscation de lien ou entités de session
L’un des problèmes fondamentaux des liens offusqués aujourd’hui est que l’on doit maintenir impérativement la liaison entre l’entité signataire du lien et une entité destinataire. C’est le seul moyen de permettre à l’entité destinataire de « recevoir » des liens d’une entité source signataire.
Mais cette liaison marque un échange entre deux entités, ce qui déjà dévoile quelque chose que l’on ne voudrait pas forcément voir apparaître publiquement. Il faut pouvoir anonymiser cette liaison.
Pour éviter le marquage de cette relation entre deux entités, il y a deux voies possibles utilisant des entités intermédiaires.
La première solution, pas forcément très élégante, est de faire une double dissimulation des liens. Le premier niveau de dissimulation fait intervenir les deux entités précédentes. Le second niveau va sur-dissimuler le lien mais cette fois-ci avec une entité signataire neutre. Chaque entité de la liaison échange génère et échange préalablement une entité neutre qu’ils s’approprient par des liens dissimulés (pour eux-même). Il faut un mécanisme d’échange préalable des entités neutres de la même façon que l’on échangerait préalablement un secret partagé.
Mais cette méthode ne marche pas avec la dernière modification de la structure du lien dissimulé qui impose au lien dissimulé le signataire du lien non dissimulé.
On peut cependant conserver la notion d’entités neutres dédiées à une échange entre deux entités. Pas besoin de sur-dissimulation, il faut juste être capable d’associer une entité neutre à l’entité d’un correspondant. Nous avons dans ce cas des entités neutre pouvant faire office d’entités de session en complément/remplacement d’une clé de session.
Anonymisation/dissimulation des liens – ségrégation partielle
Suite à l’article Anonymisation/dissimulation des liens – ségrégation et temporalité, la réflexion sur le stockage et l’échange des liens dissimulés continue.
Il était question de créer un dossier spécifique pour stocker les liens dissimulés. Le nommage des fichiers contenant ces liens doit aussi être différent des entités signataires et destinataires des liens, et ce nommage peut par facilité faire référence simultanément à ces deux entités. Mais il est possible de juste appliquer le nommage de ces fichiers dans le dossier des liens. Cette organisation et cette séparation des liens dans des fichiers clairement distincts répond au besoin. Et lors du nettoyage des liens, le traitement peut être différencié par rapport à la structure du nom des fichiers.
Le nommage proposé des fichiers contenants les liens dissimulés :
/l/HashEntitéDestinataire-HashEntitéSignataire
Le hash de l’entité destinataire est en premier, ainsi, pour une entité, tous les liens dissimulés ou non sont dans des fichiers co-localisés, c’est à dire commençant par le hash de l’entité.
Il faut par contre, lors de la synchronisation des groupes et des conversation récupérer à la fois les liens de l’objet de conversation et les liens dissimulés.
Anonymisation/dissimulation des liens – ségrégation et temporalité
Dans l’article sur l’Anonymisation/dissimulation des liens, on a vu que le stockage et le partage des liens dissimulés, de type c, était difficile si on voulait respecter le fonctionnement nominal des liens tels que définis depuis longtemps dans nebule.
Les seuls identifiants objets réels en clair dans le lien sont l’entité signataire et l’entité destinataire. Ce peut être d’ailleurs la même entité qui dissimule ses propres liens. Il n’est donc pas possible de diffuser les liens dissimulés autre part que sur l’entité destinataire.
Cependant les liens dissimulés ne jouent pas le même jeux que les liens en clair. Il faut peut-être les sortir du circuit normal des liens et mettre en place un circuit dédié.
Par exemple on peut dédier un nouveau dossier pour leur stockage, un dossier nommé c par exemple.
On peut aussi imaginer que ce dossier dédié ne serait pas structuré de la même façon. Il doit être fait référence aux entités qui dissimulent des liens, mais il est possible de segmenter encore un tout petit peu. On peut avoir des noms de fichiers de stockage des liens dissimulés faisant référence à l’entité signataire et l’entité destinataire. Ainsi il serait possible de retrouver les liens qui nous concerne et uniquement ceux-là sans avoir besoin d’un tri coüteux.
Il faut penser aussi que les liens dissimulés ne seront pas forcément horodatés correctement. Seul le champ temporel dissimulé sera exploitable pour l’entité destinataire. Les liens ne peuvent donc pas raisonnablement être pré-classés par ancienneté.
Le problème résiduel de performance tien dans le fait que lorsque l’on ouvre une session avec une entité, il faut relire et déchiffrer tous les liens même si l’on en cherche qu’un seul. Il est peut-être possible de stocker les liens dissimulés lus, et donc déjà vérifiés, dans un objet protégé. La vérification pourrait ne plus être faite systématiquement. Cet objet particulier pourrait être lui aussi dans le dossier dédié c, et donc ne pas respecter les contraintes de vérification de son empreinte, et donc de pouvoir être agrandi régulièrement. Dans ce cas la lecture des liens dissimulés se ferait beaucoup plus rapidement.
Reste à savoir quand et comment on alimente ce gros fichier tampon des liens dissimulés…
Création d’objet et dissimulation des liens
Lors de la création d’un objet, quel qu’il soit, génère au minimum un lien de définition du hash de l’empreinte. Sauf que la création par défaut de liens peut perturber voir anéantir la dissimulation de la création de l’objet.
Certains liens peuvent être dissimulés au moment de la création ou à posteriori, mais le lien de l’empreinte doit rester visible sous peine de perturber la vérification des objets. Il est possible cependant d’anti-dater le champ date de ce lien pour lui retirer toute référence à une plage temporelle de création. Mais il restera et sera un marque d’association du créateur de l’objet si par ailleurs l’objet a un lien d’usage non dissimulé, y compris d’une autre entité.
Le lien d’annulation de suppression d’un objet est moins critique, si dissimulé il fonctionnera toujours.
Les autres liens définissants des propriétés de l’objet peuvent être aussi dissimulés sans problème.
Le code de la bibliothèque nebule en php intègre ces modifications pour les objets, les groupes et les conversations. Seules les entités ne sont pas concernées, leurs contenus ne pouvant être protégés, dissimuler les liens n’a pas de sens.
Penser à supprimer le lien de l’empreinte reviendrait à faire apparaître l’algorithme dans le lien… et donc à changer significativement la forme des liens et le fonctionnement de nebule.
Anonymisation/dissimulation des liens
Il y a déjà une série d’articles en 2012 sur la Liaison secrète (et suite), puis en 2014 sur l’Anonymisation de lien (et correction du registre de lien), et enfin en 2015 sur la Dissimulation de liens, multi-entités et anonymat et l’Exploitation de liens dissimulés.
On trouve dès 2015 un schéma d’implémentation d’un lien dissimulé (offusqué) et le mécanisme cryptographique utilisé :
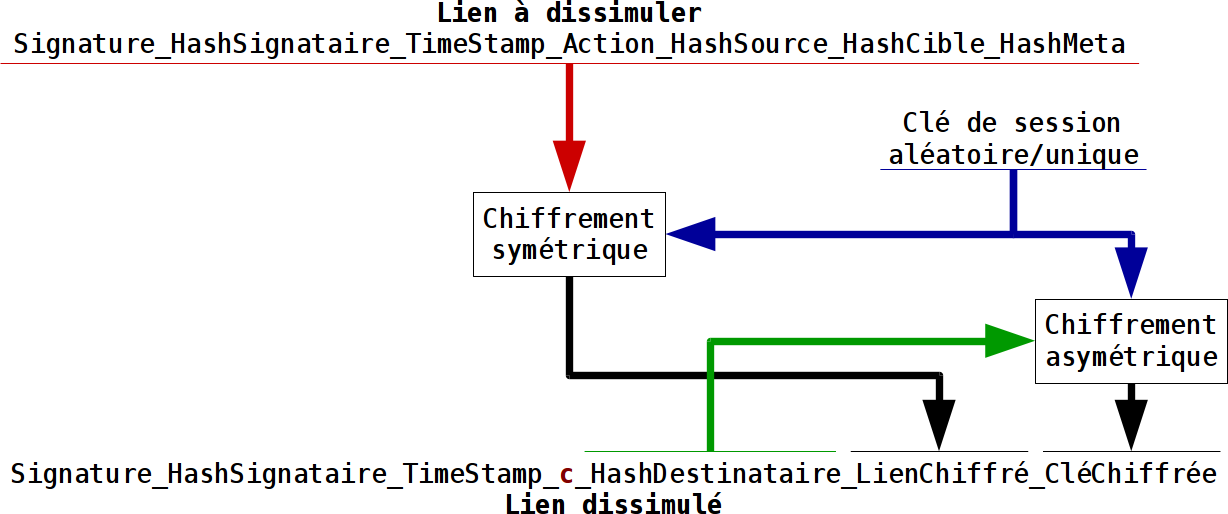
Mais la mise en pratique ne suit pas alors que la bibliothèque nebule en php orienté objet est prête à reconnaître les liens dissimulés.
Parce qu’en pratique, il ne suffit pas juste de générer ces liens et de les lire, il faut aussi les stocker de manière à pouvoir les retrouver tout en gardant des performances acceptables lors du passage à l’échelle.
Comme l’anonymisation attendue nécessite la mise en place d’un minimum de déception vis-à-vis d’un adversaire, il n’est pas possible de stocker les liens dissimulés dans les liens des objets concernés. Cela casserait presque immédiatement la confidentialité du lien dissimulé parce que les objets ont souvent chacun des rôles propres et donc des places privilégiées dans les liens qui servent aux usages de ces objets.
Les deux seules informations que l’on ne peut dissimuler sans bloquer le transfert et l’exploitation des liens dissimulés, c’est l’entité signataire et l’entité destinataire (si différente). Donc le stockage ne peut se faire que de façon connexe à des deux entités. Si ce n’est pas le cas les liens ne pourront pas être retrouvés et utilisés lorsque nécessaire.
Prenons le cas d’une entité qui décide de dissimuler la grande majorité de son activité, elle va donc dissimuler tous les liens qu’elle génère (ou presque). Là où habituellement le stockage des liens aurait été réparti entre tous les objets concernés, du fait de la dissimulation ils vont tous se retrouver attachés à un même objet, l’entité signataire. Cela veut dire que pour extraire un lien de cette entité il va falloir parcourir tous les liens. Cela peut fortement impacter les performances de l’ensemble.
Et c’est aussi sans compter le problème de distribution des liens parce que l’on les distribue aujourd’hui que vers les objets source, cible et méta… et non sur les entités signataires. L’entité destinataire est dans ce cas naturellement desservie directement, est-ce un problème si l’entité signataire ne l’est pas ?
Une autre méthode pourrait consister à créer un objet de référence rattaché à l’entité et spécifiquement dédié à recevoir les liens dissimulés. Mais les liens dissimulés ne contenant pas cette objet de référence, on doit créer un processus plus complexe pour la distribution des liens tenant compte des entités signataires et destinataires.
On peut aussi mettre tous les liens chiffrés dans les liens d’un objet c puisque c’est le type de lien après dissimulation. Mais cela veut dire que tous les liens dissimulés de toutes les entités se retrouvent au même endroit. On ne fait que déplacer le problème de la longue liste des liens à parcourir.
Enfin on peut rester sur une des premières idées qui consiste à stocker des liens dissimulés non plus dans la partie du stockage dédié au liens mais directement dans un objet. Le défaut de cette méthode est qu’à chaque nouveau lien dissimulé généré, il faut refaire un nouvel objet avec une novelle empreinte… et donc un nouveau lien pour le retrouver.
On rejoint le problème de la persistance des données dans le temps, de leurs objets et liens associés. Une solution déjà proposée, mais non implémentée, consiste à organiser un nettoyage par l’oubli des objets et des liens dans le temps en fonction d’une pondération.
Pour commencer à expérimenter, les liens dissimulés seront stockés uniquement avec l’entité destinataire. Cela ne remet pas en cause la distribution actuelle des liens. On verra à l’expérience comment gérer un flux massif de liens et son impact sur les performances.
Sondages et votes
Dans un article La Suisse pourrait imposer l’open-source pour le vote électronique de Numerama, il est de nouveau question de la mise à disposition du code source du programme sous forme de logiciel libre.
L’avenir du vote électronique ne fait aucun doute, seule sa réalisation pose problème aujourd’hui. Beaucoup de débats comparatifs et contradictoires ont lieux vis-à-vis de la pertinence du vote électronique et de la confiance que l’on peut apporter aux machines de vote et au processus dans son ensemble. Ces débats peuvent paraître très conservateurs mais ils sont néanmoins nécessaires puisque le vote est un acte fondamental de nos démocraties, c’est le moyen d’expression de chacun d’entre nous.
La confiance en ce genre de machine de vote et du code qui l’anime ne peut être assurée sans l’ouverture du code à minima en lecture. Il faut aussi connaître précisément l’environnement de compilation et d’exécution pour le code soit parfaitement reproductible. Et bien sür, il faut être sür ce c’est bien ce code qui a été utilisé et pas un autre.
Invoquer le secret industriel sur du code pour un processus parfaitement connu et un enjeu majeur de démocratie, c’est particulièrement malhonnête. Tout au plus une société éditrice peut-elle demander un droit de paternité et une restriction de commercialisation à son seul bénéfice. Mais il suffit à l’état qui fait la commande du code de demander, et payer, explicitement la libre diffusion ou la libéralisation complète du code.
Le code doit être capable dans son ensemble de permettre la centralisation des votes, l’anonymisation des électeurs ainsi que la vérification en temps réel et à postériori du décompte des votes. L’authentification de l’utilisateur devrait être le principal problème mais il apparaît que c’est en fait le décompte et sa vérification qui interpellent le plus souvent les détracteurs du vote électronique.
Un vote a un point de départ dans le temps et une fin à partir de laquelle le décompte des votes est considéré comme définitif.
L’anonymisation est aussi un problème pour la vérification de conformité du vote à postériori puisqu’elle casse le lien sür entre le votant et le vote unitaire. On peut ainsi affirmer que le votant à voté (il a posé un papier et signé le paraphore) mais on ne peut pas le prouver à postériori (était-ce vraiment lui).
La capacité de multi-entité et la dissimulation de liens dans nebule permettent de résoudre ce problème.
Voici un scénario possible de vote avec les objets et liens de nebule :
- Pour un vote, une entité maîtresse du vote est générée. Elle est explicitement reconnue par les autorités comme telle. Son seul rôle est de générer les jetons de vote et de les attribuer aux électeurs.
- L’entité maîtresse du vote va générer autant d’objets jetons qu’il y a de votants. Ces jetons sont aléatoires et n’ont pas de relation directes avec les électeurs. Chaque jeton est en fait la partie publique d’un bi-clé cryptographique (RSA par exemple). La clé privée de chaque jetons est protégé par un mot de passe stocké dans un objet protégé par et pour l’entité maîtresse (dans un premier temps).
- Le jeton est en fait l’entité qui réalisera le vote via la clé privée. Chaque vote peut être vérifié par rapport au jeton, c’est à dire la clé publique.
- Pour chaque objets de clés privées de chaque jetons, l’entité maîtresse va partager le secret de chiffrement de l’objet contenant le mot de passe. Le lien entre objet chiffré et objet non chiffré est dissimulé, c’est à dire que c’est un lien de type
cmasquant le vrai lien. - La clé privée de l’entité maîtresse est détruite. Il n’est ainsi plus possible de retrouver l’intégralité des relations en les jetons et les électeurs mais il est possible de vérifier que tous les électeurs ont reçus un lien dissimulé et de vérifier tous les jetons réalisant le vote.
- Pour un vote, une entité de décompte du vote est générée. Elle est explicitement reconnue par l’entité maîtresse Son seul rôle est de recueillir et de valider les votes. La période de vote démarre.
- L’électeur, c’est à dire l’entités votantes, va récupérer auprès de l’entité maîtresse du vote l’intégralité des jetons et des clés privées associées (et pas juste son jeton). Il va ainsi obtenir tous les liens dont le lien dissimulé le concernant. Via le lien dissimulé, il va savoir quel est la clé privée du jeton que l’entité maîtresse lui a attribué. Disposant de cette information il peut déprotéger à son profit l’objet contenant le mot de passe de la clé privée du jeton.
- L’électeur, mettant à profit la clé privée du jeton, peut réaliser un ou plusieurs votes, seul le dernier est pris en compte. Le vote consiste en un lien entre le jeton et le choix de vote dans le contexte de l’entité de décompte du vote (champs méta).
- L’entité de décompte du vote vérifie régulièrement auprès de tous les électeurs la présence de liens dont elle est le contexte. au fur et à mesure de la récupération des liens, elle se les approprie (signature du lien de vote).
- A la fin de la période de vote, la clé privé de l’entité de décompte du vote est détruite. Plus aucun vote ne peut être ajouté, modifié ou supprimé. Les votes comptabilisés sont ceux qui ont été signés par l’entité de décompte du vote.
- L’électeur qui souhaite rendre publique son vote a juste à prouver qu’il dispose du jeton en utilisant sa clé privée pour autre chose que le vote en relation avec sa véritable entité. Il peut aussi révéler le lien dissimulé que lui avait généré l’entité maîtresse du vote.
Un des aspects des liens dissimulés est qu’il est possible de les dissimuler pour plusieurs entités. Ainsi il est possible de générer une entité d’audit du vote à qui l’entité maîtresse partagera les liens dissimulés, de façon également dissimulé.L’entité d’audit devient capable à postériori de vérifier la bonne association entre jetons de vote et électeurs sans être elle-même capable d’émettre de nouveaux jetons.
Le sondage est moins contraignant et surtout peut être à choix multiples.
Attribuer des propriétés aux autres entités
Je viens de voir que dans Google Plus on peut ajouter des coordonnées à une autre personnes. Celles-ci restent confidentielles, c’est à dire juste connues de soi-même… et de Google. C’est un peu intrusif quand même puisque Google peut connaître les coordonnées d’une personne alors qu’elle ne les a pas volontairement publiées.
Dans nebule, on peut faire la même chose puisque l’on dérive d’une entité une propriété. Mais on en reste maître et, si les liens sont masqués, cela reste complètement privé. Même l’entité qui en fait l’objet ne le sait pas. La différence, c’est que on est le seul ‘strictement’ à connaître cet ajout de propriété et cela n’apparaît pas dans une base de donnée d’une grande société que l’on ne maîtrise pas.
Exploitation de liens dissimulés
Dans l’article sur la Dissimulation de liens, multi-entités et anonymat, on a vu comment implémenter des liens dissimulés dans d’autres liens.
Ici, on va apporter quelques précisions pratiques.
Déjà, un lien dissimulé va apparaître avec une entité signataire et une entité destinataire du lien. On a vu que c’était le minimum vital pour que cela fonctionne et que l’on puisse partager les liens même si cela implique de travailler sur les entités pour parfaire l’anonymisation. Il y a le cas particulier du lien dissimulé pour soi-même, dans ce cas l’entité signataire est aussi l’entité destinataire.
Lorsque l’on regarde les liens d’un objet, on va voir tous les liens non dissimulés. Si une entité est déverrouillée, il faut en plus parcourir tous les liens de type c de l’objet de l’entité pour en extraire les liens dissimulés relatifs à l’objet que l’on regardait. Dans le cas de multiples entités esclaves d’une entité maîtresse, il faut faire de même pour extraire tous les liens dissimulés pour toutes les entités accessibles. Il faut veiller dans ce cas à ce que l’interface montre clairement qui est l’entité concernée pour éviter toute confusion de l’utilisateur.
Dissimulation de liens, multi-entités et anonymat
La dissimulation de lien tel que prévu dans nebule n’est que la première partie permettant l’anonymisation des échanges entre entités.
Voir les articles précédents :
– Liaison secrète et suite ;
– Nouvelle version v1.2, Anonymisation de lien et correction du registre ;
– Lien de type c, précisions ;
– Entités multiples, gestion, relations et anonymat et Entité multiples ;
– Nébuleuse sociétale et confiance – Chiffrement par défaut
Cette dissimulation d’un lien se fait avec un lien de type c. On a bien sür dans le registre du lien visible l’entité qui génère ce lien, l’entité signataire. Et on a l’entité destinataire qui peut déchiffrer ce lien dissimulé et en extraire le vrai lien. Et comme dans la version publique de ce lien on a à la fois l’entité source et l’entité destinataire qui sont visibles, il n’y a pas d’anonymat. Ce type de lien permet juste de dissimuler l’usage d’un objet.
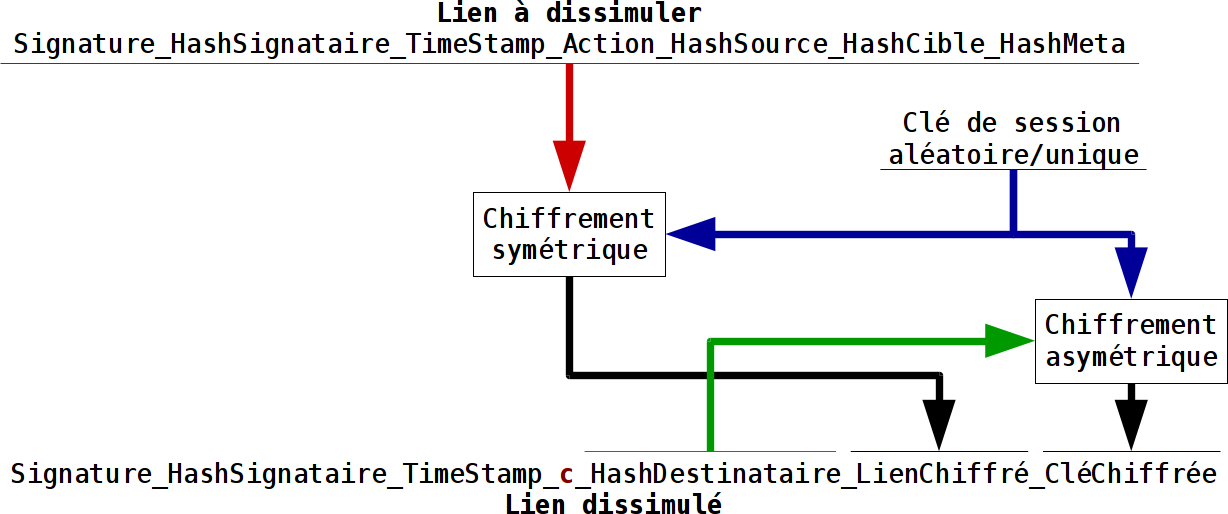
Un lien dissimulé ne peut pas contenir un autre lien dissimulé. On interdit donc les multi-niveaux de liens dissimulés qui seraient un véritable calvaire à traiter.
Un lien peut être dissimulé pour soi-même. C’est à dire que l’entité signataire est aussi l’entité destinataire.
Si un lien doit être dissimulé pour plusieurs destinataires, il faut générer un lien pour chaque destinataire. La seule façon de réduire le nombre de liens pour un grand nombre de destinataires est d’utiliser la notion de groupe disposant de son propre bi-clé. Ce type de groupe est pour l’instant purement théorique.
Ce maintien comme public des entités sources et destinataires est une nécessité au niveau du lien, c’est une des bases de la confiance dans les liens. Pour que le lien puisse être validé et accepté par une entité ou retransmit par un relais, l’identification des entités est incontournable. Et donc avec l’identification nous avons aussi l’imputabilité et la non répudiation.
Si on veut assurer de l’anonymat pour les entités, puisque l’on ne peut pas travailler au niveau du lien, il faut travailler au niveau de l’entitié. On va dans ce cas travailler sur la notion de déception, c’est à dire faire apparaître des entités pour ce qu’elles ne sont pas ou tromper sur la nature des entités.
L’idée retenu consiste, pour chaque entité qui souhaite anonymiser ses échanges avec une autre entité, à générer une entité esclave avec laquelle elle n’a aucun lien. Ou plutôt, le lien d’entité maîtresse à entité esclave est un lien dissimulé pour l’entité maîtresse uniquement. Ici, personne à par l’entité maîtresse ne peut affirmer juste sur les liens que l’entité esclave lui est reliée.
Lorsque l’on veut échanger de façon anonyme, on transmet à l’entité destinataire l’identifiant de l’entité esclave, et vice versa. Cette transmission doit bien sür être faîte par un autre moyen de communication ou au pire par un seul lien dissimulé.
L’anonymisation complète est donc la combinaison des liens de dissimulation de liens et d’une capacité multi-entités des programmes.
La dissimulation est en cours d’implémentation dans sylabe en programmation php orienté objet. Mais le plus gros du travail sera à faire dans la librairie nebule puisque c’est elle qui manipulera les liens et présentera ceux-ci à l’application, c’est à dire sylabe, dans une forme exploitable. L’application n’a pas à se soucier de savoir si le lien est dissimulé, elle peut le lire ou elle ne peut pas. Tout au plus peut-elle afficher qu’un lien est dissimulé pour information de l’utilisateur.
La capacité multi-entités de sylabe est maintenant beaucoup plus facile à gérer en programmation php orienté objet. Mais il reste à implémenter la génération des entités esclaves avec dissimulation de leur entité maîtresse.
Une autre dimension n’est pas prise en compte ici, c’est le trafic entre les serveurs pour les échanges d’informations. Il faudra faire attention à la remontée possible aux entités maîtresses par leurs échanges.
Enfin, pour terminer, aujourd’hui c’est la course au chiffrement par défaut de tous les échanges pour tout un tas de programmes et services sur Internet. Ce chiffrement par défaut est bon pour l’utilisateur en général. Et il masque dans la masse les échanges pour qui la confidentialité est critique. Ainsi il ne suffit plus d’écouter le trafic chiffré pour retrouver ses ennemis.
Mais cette logique est perverse. Le chiffrement par défaut est une aberration, un remède de cheval posé en urgence faut de mieux. Nous avons besoin d’échanger aussi des choses publiquement, comme sur un forum ou dans la presse. Nous ne devrions pas avoir des outils de communication tout chiffré et d’autres tout public, chaque outil devrait permettre les deux et clairement indiqué ce qui est protégé de ce qui ne l’est pas…
Gestion du temps et anonymisation
L’horodatage des liens est important pour leur interprétation. C’est particulièrement vrai pour démêler les suppressions. L’horodatage est placé dans les liens, ce qui veut dire que ce n’est pas l’objet qui est daté mais son usage.
On traite ici la suite des articles Horodatage, suite, Gestion temporelle partielle, Transfert de liens et de confiance, et cela entrera dans l’Etude du temps.
Vis-à-vis de l’anonymisation des entités, et surtout des personnes derrières, la gestion du temps nécessaire à l’horodatage peut poser problèmes.
Le problème c’est la synchronisation sur une source unique. Utiliser deux ou trois source réduit le problème mais uniquement de façon linéaire. Cette source unique sera régulièrement consultée et donc verra la source des demandes, notamment d’un point de vu adresses sur le réseau. Mais qui dit demande de synchronisation de temps ne veut pas dire présentation de l’entité qui le demande. La corrélation peut être faite après coup en comparant les marques de synchronisation de temps d’une entité avec les logs de connexion. Le risque ici est de récupérer la localisation d’une entité. Pour beaucoup de personnes, la connexion à son système d’information se résume à son ordinateur à la maison, son téléphone/tablette et à son travail. Avec la connexion depuis le domicile, on peut casser assez facilement l’anonymisation.
L’utilisation de plusieurs moyens informatiques pas forcément synchronisés entre eux en terme de temps introduit des problèmes pour calculer un décalage de temps et une dérive éventuelle. Dans ce cas, la relation entre entité et localisation ou entre entité et individu est plus dure à obtenir, mais pas impossible.
On peut utiliser la même entité source de synchronisation de temps mais en passant par des relais. Il faut dans se cas récupérer les dernières marques de l’entité de gestion du temps et le rejouer. En passant par une entité intermédiaire, on casse la corrélation possible entre les connexions et les marques de temps. C’est au prix d’une moins grand précision dans le calcul du décalage de temps.
Si on utilise un système de synchronisation des machines, tel que NTP, les machines se synchronisent sur des références de temps cohérentes. Noyé dans la masse des connexions, les synchronisations d’une entité ne permettent pas de lever son anonymat. Malheureusement, cela ne fonctionne que si les machines sont en réseau. Tout au plus peut-on se contenter d’une synchronisation irrégulière et espacée dans le temps. Dans ce cas, l’absence de marques de temps d’une entité ne permettra pas de calculer son décalage, et donc on en sera réduit à supposer qu’elle est à peu près à l’heure.
Dans tous les cas, il est possible d’utiliser en même temps une synchronisation précise par NTP et un calcul de décalage de temps. Des machines synchronisées devraient avoir un décalage proche de 0. Pour ne pas affaiblir l’anonymat des utilisateurs, il est préférable d’avoir une synchronisation NTP et d’utiliser les marques de temps mais horodatées sur son heure propre. Les marques de temps seront récupérées aléatoires chez les entités connues.
La gestion du temps va générer un trafic propre tant en réseau qu’en terme d’objets et de liens. Il faudra prévoir un nettoyage fréquent et à court terme de ces objets et liens avant qu’ils ne saturent les échanges entre entités.
Enfin, cela n’a peut-être pas trop d’importance à première vue mais c’est quand même une entorse à l’anonymisation, générer des marques de temps régulières pour permettre les synchronisations ne peut se faire que lorsque l’entité est déverrouillée. C’est à dire que l’on a des marques de temps que quand on est connecté, ce qui trahi les heures de présence effective mais aussi fait office de marqueur de présence. La parade est de ne faire des marques synchronisation de temps que… de temps en temps. Cette parade se fait au prix d’une perte de précision dans le calcul du différentiel de temps, surtout avec des machines multiples.
Entités multiples
Dans la suite des réflexions sur Entités multiples, gestion, relations et anonymat, le développement de la librairie nebule en php continue en tenant compte de cette possibilité.
En gérant le mot de passe d’une entité dans l’objet (php) de cette entité, on peut avoir plusieurs entités déverrouillées à un instant donné. Et comme plusieurs entités sont potentiellement déverrouillées, lorsque l’on consulte un objet chiffré, il ne faut plus seulement regarder si l’entité courante est déverrouillée et donc peut le lire, mais il faut regarder dans tous les destinataires si une des entité n’est pas déverrouillée aussi. Une seule suffit pour déchiffrer l’objet et afficher son contenu.
Il faut cependant faire attention à ce que l’entité courante ait bien l’accès à l’objet chiffré avant de permettre son utilisation parce que cela dévoilerait immédiatement le lien de parenté entre les deux entités. Il est imaginable de basculer immédiatement d’entité courante sur une action de ce genre.
Si on souhaite une bascule complète sur une entité esclave sans interférence d’autres entités, il suffit de vider le mot de passe de tous les objets (php) des entités que l’on ne souhaite plus voir. Cela inclut aussi l’ancienne entité courante qui peut avoir été préalablement sauvegardée avec sont mot de passe pour une restauration ultérieure.
Une des applications de cette capacité multi-entité, c’est le cumule d’entité lors d’un Changement d’identifiant d’entité. Il est possible, le temps de migrer les liens, de pouvoir continuer à consulter les objets de l’ancienne entité tout en utilisant la nouvelle entité.
Entités multiples, gestion, relations et anonymat
On peut raisonnablement penser que chaque personne, sauf problème, a une personnalité unique. Et donc qu’une personne a un comportement unique et un réseau sociale unique.
Mais la réalité n’est malheureusement pas aussi simple.
Ne prenons que l’exemple de l’individu employé dans une société. Cet environnement est à considéré comme différent de l’environnement de vie normal, c’est à dire chez soi, dans la vie privée. Au travail, nous avons des « amis imposés par l’employeur » qui forment un réseau social souvent fortement découplé du réseau social privé. Nous avons aussi des attitudes différentes, en phase avec les attitudes que l’entreprise attend de nous. Nous sommes en short à la maison, avachi devant la télévision alors que l’on est en costume 3 pièces au travail, bien assit devant son ordinateur. Les réseaux sociaux ainsi que les échanges avec les autres individus évoluent avec l’environnement dans lequel on se situe. Chacun de nous est unique mais chacun de nous adopte une pseudo-identité variable dans l’espace et le temps. Enfin, on mélange rarement les informations de ces différentes pseudo-identités. On parle rarement en détail de sa journée de travail avec des amis le weekend autour du barbecue.
Sur un réseau social numérique, comme Facebook ou Google+, imposer une identité unique est donc une vision réductrice de l’individu humain. En cherchant à n’avoir que des identités réelles des individus, on se coupe de toutes leurs identités annexes. Et une relation de travail fait typiquement d’une identité annexe.
On ne s’attardera pas ici plus longtemps sur la justification des entités multiples mais plutôt sur la technique et les possibilités que cela ouvre.
Les premières expériences avec les identités dans nebule montrent qu’un individu peut, bien évidemment, avoir plusieurs entités différentes. Chaque entité peut avoir une « vie » propre, c’est à dire un réseau social à part. Une entité peut mettre en place des entités esclaves, elles sont dans ce cas parfaitement autonomes. Elles restent autonomes même si elles sont tenues par une entité maitresse.
L’entité puppetmaster est le premier exemple d’entité maitresse. Il y a dans ce cas une idée de validation forte. On peut avoir d’autres types de relations entre entité maitresse et entités esclaves. On peut avoir des cas où la validation serait au contraire réduite voir dissimulée, dans les cas où l’anonymat est recherché.
Vis-à-vis de l’interface homme-machine, la notion même d’entités multiples n’est pas triviale. Sur nos systèmes d’information actuels, sur nos ordinateurs, téléphones, tablettes, etc… il est courant de disposer de plusieurs comptes utilisateurs. Mais on ne peut utiliser simultanément qu’un seul compte à la fois. Tout au plus peut-on changer temporairement d’identité (élévation de privilèges par exemple). Chaque action se fait sous une et une seule identité.
Si on utilise plusieurs comptes de messagerie ou comptes de réseaux sociaux numériques, il faut quitter un compte pour pouvoir accéder à un autre.
Dans une interface exploitant nebule, il est cependant possible de travailler de la même façon ou différemment.
On peut disposer de plusieurs entités et se connecter à une et une seule entité à un instant donné.
On peut aussi se connecter à une entité maitresse et basculer, immédiatement après, vers une des entités esclaves. C’est déjà fonctionnel dans sylabe. Il est même possible de revenir facilement vers l’entité maitresse pour éventuellement repartir sur une autre entité esclave. Ainsi on évolue dans des environnements isolés via des entités autonomes. De plus, la relation entre l’entité maitresse et les entités esclaves peut être masqué (offusqué).
Mais il est possible d’aller plus loin. On peut tout à fait imaginer exploiter simultanément plusieurs entités. Cela permet d’avoir une vue synthétique de plusieurs réseaux sociaux ainsi que des échanges associés. Le cloisonnement dans ce cas est invisible pour la consultation tout en restant potentiellement très fort entre chaque entités. En pratique, on pourrait voir les activités de tous les « amis » de toutes les entités esclaves que l’on contrôle même si chaque entité esclave n’a strictement aucun rapport ou aucun lien avec les autres entités esclaves. Il faut par contre définir une entité avec laquelle on agit par défaut, au risque de casser le cloisonnement des entités par des liens inappropriés. On peut même imaginer que des interactions avec un réseau social particulier se fassent avec l’entité esclave attaché au réseau en question, on conserve ainsi le cloisonnement des entités mais pas celui de l’information. En somme, c’est un peu ce que l’on fait déjà avec un logiciel client messagerie et plusieurs comptes de messagerie…
Facebook et l’anonymat
Les positions bougent aussi du côté de Facebook. Dans la suite de l’article précédent sur Google+ et l’anonymat, c’est au tour du premier réseau social de faire des concessions sur la possibilité de créer des comptes anonymes… dans une certaine mesure.
Depuis le 1er octobre, il est possible d’utiliser un pseudonyme. Tout n’est pas encore permit mais l’avancée est de taille alors que la vie privée n’était clairement pas la priorité de Facebook. Et l’anonymat était même malvenu jusque là pour inciter les internautes à avoir de vraies relations d’amitié. Il était aussi quand même plus intéressant pour les publicitaires de disposer d’informations fiables sur les utilisateurs…
Depuis peu, une nouvelle messagerie est en cours d’élaboration, par Facebook, pour permettre des échanges volontairement anonymes. Un vrai retournement… ou une opportunité commerciale de plus…
CF :
– http://www.lemonde.fr/economie/article/2014/10/02/les-pseudonymes-finalement-autorises-sur-facebook_4498801_3234.html
– http://www.lemonde.fr/pixels/article/2014/10/08/facebook-va-lancer-une-application-permettant-des-echanges-anonymes_4502637_4408996.html
Téléchargement et pondération – activation
Suite aux réflexions sommaires de Téléchargement et pondération, la mise en place commence dans le code de la librairie.
Cependant, le fait de créer par défaut un lien de pondération pour une localisation peut poser problème. Les liens générés peuvent être exploités comme des traces de l’activité d’une entité. C’est une façon de savoir quand une personne, à qui appartient l’entité, est connectée et de suivre les connexions dans le temps.
Il y a deux parades à ça. La première, interdire par défaut les synchronisations sauf si c’est explicitement demandé. La deuxième, c’est de ne pas ajouter automatiquement la pondération aux localisations lors des synchronisations.
La première solution est plutôt à gérer du côté d’une application de type sylabe.
La seconde solution est à intégrer dans la librairie php sous la forme d’une option.
Nébuleuse sociétale et confiance – Chiffrement par défaut
La relation entre les êtres humains est resté assez stable dans son contenu mais à beaucoup évolué dans sa forme avec la technique. Le la taille d’un village, d’une tribu, la dimension du réseau social d’un individu a fortement grandi et a cessé de coller à sa zone géographique proche. Mais il n’a pas forcément grossi pour autant, il ne s’est que dilaté. Il garde d’ailleurs une forme nébuleuse dense au centre et distendu en périphérie.
Le téléphone a accéléré la vitesse de transmission des informations et de fait a permis d’étendre encore plus la portée des échanges, et donc l’influence des individus. Cette extension a fini par atteindre sa taille limite, celle du monde.
Mais les échanges d’informations ne se limitent pas à l’influence, politique, des autres. On y retrouve des choses qui n’ont pas grand intérêt à première vue comme la correspondance familiale ou la propagation de la culture. Cependant, ces deux exemple ont une importance profonde dans l’identité de l’individu d’une part et de la société d’autre part.
Le réseau social individuel n’est plus depuis longtemps calqué sur son influence physique directe. Si il n’est pas évident de parler de réseau social d’un groupe d’individus, ou société, on peut quand même se raccrocher à son influence directe. Et l’influence des sociétés ne sont que rarement exactement calquées sur leurs influences physique directe, c’est à dire sur les frontières d’un pays.
Une société ne doit pas être vue comme une forme nébuleuse unique de relations sociales mais comme une forme nébuleuse sociétale composée d’une multitudes de formes nébuleuses entremêlées. Une société est composée d’une multitude de formes nébuleuses individuelles avec quelques structures communes, mais surtout, pour les individus, avec une majorité de liens au sein de la nébuleuse sociétale. Le nationalisme ou communautarisme, du point de vue du réseau social, sont des tentatives pour imposer des structures uniques fortes et donc de forcer la nébuleuse sociétale à se scinder en de multiples formes sous-sociétales. Il existe une multitude de formes sous-sociétales susceptibles de développer une forme de communautarisme puisqu’il est en pratique impossible d’avoir une nébuleuse individuelle approchant la forme nébuleuse sociétale dans son ensemble. Le nationalisme use de sa forme de nébuleuse sociétale pour revendiquer une influence physique y compris hors des frontières de l’état qui le définit à l’origine.
Le réseau Internet est un support d’information, il permet de diffuser la connaissance à tout un chacun. Mais ce n’est pas sont seul rôle, il permet aussi de relier les individus. C’est à dire qu’il sert de support universel à la forme nébuleuse des relations sociales d’un individu. Nous avons encore des échanges sociaux directs entre individus, instantanés, mais ils ne sont plus ni exclusifs ni même nécessaires ou systématiques.
Le projet nebule se doit donc de faciliter le partage de l’information, de la connaissance, mais il se doit aussi de faciliter les échanges sociaux entre individus. Le projet nebule doit être capable de coller au plus prêt de la nébuleuse de l’information d’un individu, mais aussi de la nébuleuse de son réseau social.
La messagerie telle qu’elle a commencée était un message manuscrit sur un support papier ou équivalent et pouvait mettre plusieurs mois pour arriver à destination… quand ça arrivait…
Aujourd’hui, un message traverse le monde en quelques secondes avec une très grande probabilité d’arriver à destination. Le plus long, c’est maintenant d’attendre que le destinataire ouvre son message. Tout le monde fait confiance à la messagerie électronique et à une bonne confiance dans les échanges postaux nationaux et internationaux.
Et puis il y eu Edward SNOWDEN.
La confiance, c’est la capacité du système à fonctionner tel que l’on s’attend à ce qu’il fonctionne et à être résistant aux tentatives de détourner son fonctionnement.
Là, subitement, on a une grosse crise de confiance. On se dit qu’on ne va peut-être pas laisser tous ses Å“ufs dans le même panier. Le projet nebule peut sous cet éclairage paraître un peu trop intrusif et exclusif (des autres).
Cette crainte vis-à-vis du projet nebule est à la fois recevable, et non recevable.
Le projet sylabe, annexe de nebule, est une implémentation suivant les paradigmes actuels en terme d’échange de l’information, et surtout en terme de concentration de l’information. Il est conçu volontairement dès le début pour centraliser les données sur un serveur de l’Internet. C’est cette concentration sur une machine que l’on ne maîtrise pas qui pose de gros problèmes aujourd’hui. C’est cette concentration sur des machines chez des grosses sociétés au USA qui permet à la NSA (entre autres) de violer l’intimité numérique des individus sans raison valable. Et c’est fait de telle façon que les individus gardent confiance dans cette concentration de leurs données.
Mr SNOWDEN a cassé la confiance que nous avions dans la concentration de nos données, la confiance pour ces grosses sociétés américaines, et la confiance dans l’Internet même. Il a montré que quelque chose ne fonctionnait pas bien. Mais il l’a fait pour que ça s’améliore, pour que nous fassions les efforts nécessaires pour reconstruire l’Internet et la confiance que l’on attend de lui.
Le projet sylabe est donc un reliquat de ce passé. Mais il apporte quand même quelque chose pour le futur. Il centralise les données mais contient les graines de leur décentralisation complète.
Si tout le monde n’est pas prêt aujourd’hui à installer un serveur pour héberger ses données, on y arrive quand même de façon détournée. Certains installent des boîtiers NAS, c’est déjà une forme de réappropriation de ses données. Toutes les maisons ont une box qui fait office de centre multimédia, de NAS. La domotique arrive tout doucement (depuis 20 ans). Ainsi, une instance sylabe pourra être un jour implémentée facilement dans un boîtier pour non seulement héberger nos donnés mais aussi pour nous permettre d’échanger avec nos amis.
Le projet sylabe, une fois implanté ailleurs que sur des serveurs centralisés permettra la mise en place complète de la vision de la nébuleuse de nos informations, complètement décentralisée mais centrée sur nous.
Il reste à traiter le problème de l’anonymat. C’est en cours de définition et d’implémentation.
Cet objectif à part entière, dans le contexte actuel, nécessite qu’une entité puisse nativement et par défaut chiffrer tous ses objets et offusquer tous ses liens, ou presque tous. Cette possibilité sera intégrée rapidement dans le projet sylabe.