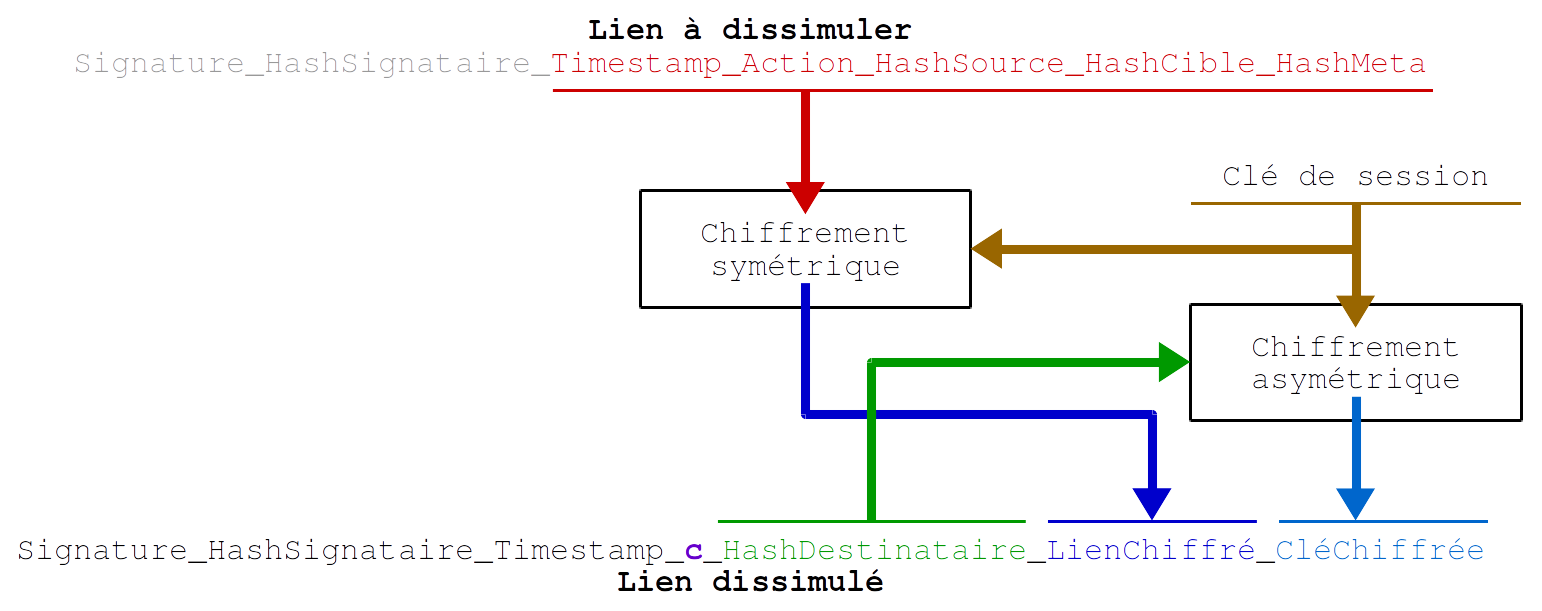
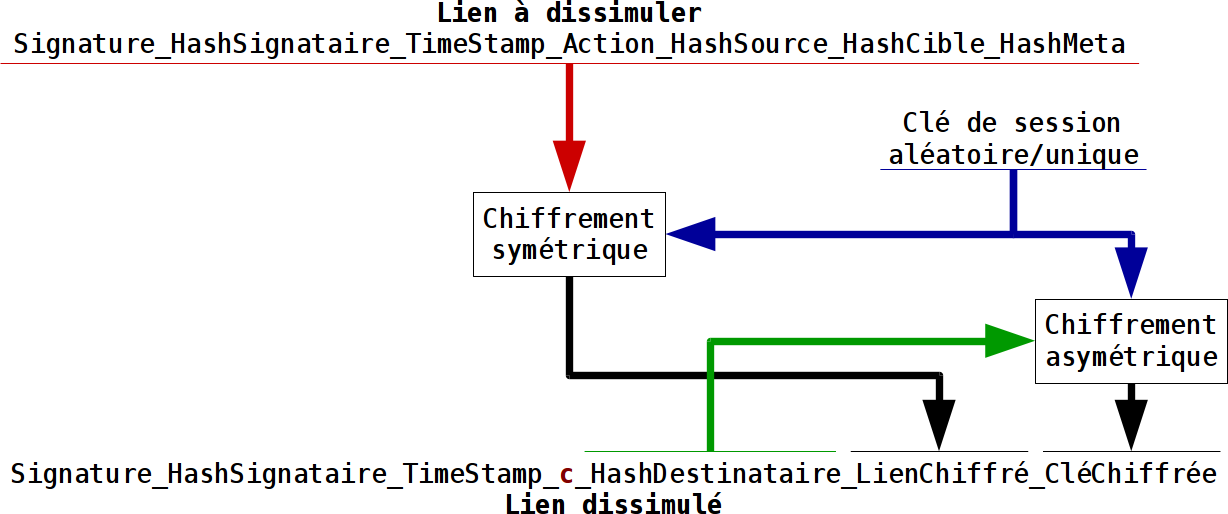
Les deux premiers liens dans la nouvelle forme en v2.0 viennent d’être signés :
nebule:link/2:0_0:020210714/l>88848d09edc416e443ce1491753c75d75d7d8790c1253becf9a2191ac369f4ea.sha2.256>5d5b09f6dcb2d53a5fffc60c4ac0d55fabdf556069d6631545f42aa6e3500f2e.sha2.256>8e2adbda190535721fc8fceead980361e33523e97a9748aba95642f8310eb5ec.sha2.256_88848d09edc416e443ce1491753c75d75d7d8790c1253becf9a2191ac369f4ea.sha2.256>79bf4029cf6ee77b0f9db987fcb59c53434a8f2e36773d7a427ec869de04698ddb044bfe08d963732dec237ef56b03f003f4bcc491e293c0b6a7396a351b10e319aa80984bd5d7c0c812cd6a91a296d55ace2e6e6d266dd06c83f21814e272793e75e23cb8f70911ba845885f9e41636466b74e6a7f7e1c174e612776981e645273ac59410ab39606feb20102cf28834aa054008bb35191573189bb0266875dd82cbf12dc64d0eb77acf59e18c8336583faac32755450c00d559398fbd078871fcd9097ac476f67010a9d728a00860f1e34f66bd32b64093b834fcce2bf028193335ebedd1ae27e29df3b8184360bee9dbc707135c54ef48d3efc096b32ba33681925afb8d4e7d4f91598f4d250eb9d27b96762727610a87317892033e84e6e7198837a10ef5e8582ecb98d6aef00e7b4ef2d536cb2063b476d21a8abaf6678462e329bf08bb9159ec4a7358b1e6b15252bd1acf471eb43895edc4caaee58e9d1fcd36cd21b7fc45fb43443c3408de80c1aa3d8c45c71071bfebbfa0c82f747e97f0668d628a3bb5f18cf105b5c16ac14fa61730fdf97342add718ee6c55cf576b060027ce5dfd3651349ff3163011f58cdc2140ea3ef9d2bfefe1d105498722b6ff3c0993aaffa0f0625e5bd2503cf289ec3e694b43616134d1a938dfe1d050b4106f466b23c2dc446e7f1d96a942aaa73c694a8434bdf549fde985ff939142.sha2.512
nebule:link/2:0_0:020210714/l>88848d09edc416e443ce1491753c75d75d7d8790c1253becf9a2191ac369f4ea.sha2.256>970bdb5df1e795929c71503d578b1b6bed601bb65ed7b8e4ae77dd85125d7864.sha2.256>5312dedbae053266a3556f44aba2292f24cdf1c3213aa5b4934005dd582aefa0.sha2.256_88848d09edc416e443ce1491753c75d75d7d8790c1253becf9a2191ac369f4ea.sha2.256>58ca04cc43fc46c7a5176f2ff8f93754da9cfaabff2f12a3c9e6453d3dd3eeedd0208477f9e62c085a6f32583a127467696d7af980fe18a85a7951a6deea6372ca9f0c965d0a08fa159f241a680d5dba69449acb03043fc8021b93a2e34a1c3fb93385250f5ebf7a457fd38f2c6b1e500614f19b37bd37416342ddd94385ec2f5185fddde6d803fc1f89dabe6aebcd55490688cdbe5c779ae2b81d7a4b65c57fd6b35b6ad0fb20881f12c04e34a1730e254530a9c69fdaa9c1ef76fa6248a6e22417e25758837c7378f97af5c3d2cfe88fe9711ba705e2d017fe7ff4c97cbb44600e0d7b32e1c2f97467d8e79d48fc5d6dbd3d581bb831582be7f1a918609cd4a64e4d621bababaddde6da3621f24220ed7dc2ae585fe9b7f9cd71fe18a1a75778c54bdf1e7ad066e10c36e7fb2a4577f9d1bc7be1f80363d1a3e58e34ee4971ccd0a8a8b45665b1234909104558cb210ea402cb7822e3f4c5e1095c4f6a8a86b432b7c77028c76d38dd171a009dd7b251f74ea112739b91cfd8a6c665546bb984dc2fd1f59212a59f84154556bcdfade82c1b049e91a1befa45f2511f02123aa3f7718b0c64aeca984eb70cb9841e933603221765899384e1d3467cb31071ae3071e741f9689735a7e0c8cf7e202b926260067112fec8b24f991a6b35868fbb3653f2be774574d87e1a0fe9222774f6ede5b38c8393d72ff866faa40c5b706f.sha2.512Ces deux liens concernent l’entité puppetmaster et sont ceux posés par défaut lors du premier lancement du bootstrap, lorsqu’il n’y a encore rien d’autre.
Ils sont la particularité d’avoir une signature faite sur un hash à 512bits.