Pour les blogs, les dossiers, les galeries et bientôt les messageries, les liens qui définissent les différents niveaux ont été changés. Ce sont maintenant des groupes typés. En effet, à l’usage il apparaît que tous ces objets, souvent virtuels, peuvent être manipulés simplement comme des groupes avec des éléments, à condition d’être préalablement définis comme tel.
Catégorie : groupes
Graphe des entités autorités
Afin d’organiser une certaine intendance autour de la diffusion du code des applications, un certain nombre d’entités sont nécessaires.
Le modèle utilisé est assez classique est simple, c’est un schéma de parenté. Il peut être amené à évoluer dans le futur.
La structure du graphe reconnue est la suivant :
- Le maître du tout (puppetmaster)
- Les autorités de la sécurité
- Les autorités du code
- Les autorités du temps
- Les autorités de l’annuaire
Une évolution est en cours d’intégration avec la nouvelle version des liens. Si l’entité qui chapeaute toutes les autres est unique, chaque groupe d’autorités n’est plus seulement une entité mais devient un groupe d’entités à pouvoir identique.
Il est à prévoir que le maître du tout deviendra aussi, un jour, des autorités globales. Mais la forme n’est pas encore défini.
Chaque entité ici considérée doit être un objet entité EID (Entity ID) valide avec lien de type, un lien de nommage et un lien de localisation (URL web).
D’un point de vue sémantique, on quitte progressivement la notion de maître historique pour aller vers la notion d’autorité. Outre le rapport à l’esclavage, on est soumis au maître, on se soumet à l’autorité.
Le puppetmaster est un EID qui peut être remplacé. Il va faire référence par des liens dédiés vers les différents d’autorités au moyen de RID dédiés :
- Autorités de la sécurité
a4b210d4fb820a5b715509e501e36873eb9e27dca1dd591a98a5fc264fd2238adf4b489d.none.288
- Autorités du code
2b9dd679451eaca14a50e7a65352f959fc3ad55efc572dcd009c526bc01ab3fe304d8e69.none.288
- Autorités du temps
bab7966fd5b483f9556ac34e4fac9f778d0014149f196236064931378785d81cae5e7a6e.none.288
- Autorités de l’annuaire
50e1d0348892e7b8a555301983bccdb8a07871843ed8f392d539d3d90f37ea8c2a54d72a.none.288
C’est à dire que tout EID désigné par un de ces RID (l>RID>EID), et signé par le puppetmaster, devient une autorité dans le groupe considéré.
Nœuds et références
Entre le nœud et la référence, peu de différence à voir. C’est surtout un usage dans le code.
La référence RID (Reference ID) est un nœud NID que l’on utilise explicitement comme point de départ d’une recherche d’objets.
Là o`u un NID différent va être utilisé pour désigner chaque groupes, un RID va être unique pour retrouver une propriété.
Par exemple une conversation est un groupe de messages. Mais chaque conversation est unique, chacune dispose d’un NID propre.
Le suivi d’un code d’une application se fait en récupérant le dernier lien depuis un RID. Mais on peut aussi voir ce RID comme un groupe des versions successives de cette application.
Le nommage d’un RID n’a pas de raison d’être même si ce n’est pas interdit.
Application d’authentification et gestion des entités déverrouillables
La gestion des entités déverrouillables sur une instance de serveur est pour l’instant rudimentaire. Toute entité qui réussi à poser une clé publique et une clé privée sur l’instance peut se connecter. Il serait intéressant de pouvoir restreindre ces entités à un groupe connu et alimenté par les autorités locales. Ce groupe pourrait être vu comme un annuaire. On peut imaginer aussi un mécanisme de cooptation. Et on peux imaginer un bannissement sur liste noire même si cette méthode doit être couplée à un autre mécanisme.
Dans la lignée de la réflexion, il pourrait être intéressant de déléguer l’authentification à une application dédiée avec retour à l’application d’origine si ça se passe bien.
Cosignature et validation de transactions
Un mécanisme de cosignature fonctionnant sur le principe de quota peut être une réponse possible à la validation de transactions dans un groupe fermé d’entités. La difficulté est que chaque entité peut ne pas reconnaître la même composition du groupe du fait du traitement social des liens du groupe. Mais si le groupe est explicitement définit dans l’objet de groupe avec le quota attendu, alors cela devient jouable…
Réorganisation des entités spéciales – groupes d’entités
Suite de l’article Réorganisation des entités spéciales – inventaire de départ.
Le regroupement d’entités par rôle correspond à la création d’un groupe d’entités, groupe auquel on va donner le rôle. Il va être possible avec le groupe de définir de nouveaux filtres sociaux de tri des liens. Ces filtres viendront remplacer un filtre historique, restricted, qui a un rôle important mais dont le nom devient ambiguë.
Par exemple, à l’entité maître du code bachue il sera possible d’adjoindre d’autres entités pour valider du code. Cela permet de recréer l’équivalent de l’ajout de plusieurs dépôts logiciels différents. Il est même envisageable pour une entité de désactiver bachue spécifiquement du groupe.
L’entité locale de l’instance va aussi avoir des droits plus étendus. Elle pourra être, via des options, équivalente à toutes les autorités globales, y compris le maître du tout (puppetmaster). Bien sür ces droits ne seront valables que sur l’instance de serveur qui lui est rattachée… et toute entité qui décidera de l’ajouter dans un groupe de droits.
Création d’objet et dissimulation des liens
Lors de la création d’un objet, quel qu’il soit, génère au minimum un lien de définition du hash de l’empreinte. Sauf que la création par défaut de liens peut perturber voir anéantir la dissimulation de la création de l’objet.
Certains liens peuvent être dissimulés au moment de la création ou à posteriori, mais le lien de l’empreinte doit rester visible sous peine de perturber la vérification des objets. Il est possible cependant d’anti-dater le champ date de ce lien pour lui retirer toute référence à une plage temporelle de création. Mais il restera et sera un marque d’association du créateur de l’objet si par ailleurs l’objet a un lien d’usage non dissimulé, y compris d’une autre entité.
Le lien d’annulation de suppression d’un objet est moins critique, si dissimulé il fonctionnera toujours.
Les autres liens définissants des propriétés de l’objet peuvent être aussi dissimulés sans problème.
Le code de la bibliothèque nebule en php intègre ces modifications pour les objets, les groupes et les conversations. Seules les entités ne sont pas concernées, leurs contenus ne pouvant être protégés, dissimuler les liens n’a pas de sens.
Penser à supprimer le lien de l’empreinte reviendrait à faire apparaître l’algorithme dans le lien… et donc à changer significativement la forme des liens et le fonctionnement de nebule.
Nouvelle version librairie php
Diffusion de la nouvelle librairie en php. Elle intègre nativement la gestion des conversations. La modification de la gestion des groupes n’est pas encore faite.
Le code : 9826667246765674e690e914bfc0a524f2847651f49f8ea1e638bb4122a3b4b4
Gestion des conversations
La librairie php en cours de développement intègre maintenant nativement la gestion des conversations. Les conversations permettent de suivre des messages.
L’intégration dans la librairie permet de décharger les programmes comme sylabe et klicty de la gestion de ces conversations. Il permet aussi une uniformisation de cette gestion.
La gestion des conversations est au départ copiée/collée de la gestion des groupes. Mais elle a été revu au cours du développement.
Les conversations peuvent maintenant être marquées comme :
- fermée (ou ouverte)
- protégée (ou publique)
- dissimulée (ou affichée)
La fonctionnalité de conversation fermée est fonctionnelle, la protection est en court de développement et la dissimulation n’est pas encore développée.
L’intégration des groupes va être revu pour fonctionner de la même façon que les conversations.
Norme nebule v1.2
La documentation technique de nebule en version 1.2 est maintenant intégrée comme une page au blog. Elle passe en même temps de documentation à norme.
La partie concernant les groupes est agrandie.
Entités de recouvrement
Le mécanisme de recouvrement des objets protégés et des liens dissimulés est en train d’être doucement mis en place.
D’un point de vue théorique, cela répond à deux problèmes similaires.
En entreprise, et pas que, il est recommandé d’utiliser une ou plusieurs autorités de recouvrement lorsque l’on utilise de la cryptographie pour protéger ses données. Les décideurs le prennent souvent comme une contraite et oublient de mettre en place ce mécanisme de restauration des données chiffrées. Et ce mécanisme est différent de celui de restauration classique alors qu’il est perçu comme étant le même. Résultat, lorsqu’un employé critique vient à manquer, ses données, critiques aussi, deviennent subitement inaccessibles. La disponibilité c’est aussi de la sécurité.
Pour différentes raisons, des états plus ou moins démocratiques peuvent imposer la mise en place d’un mécanisme de déchiffrement des données de leurs concitoyens.
Mais, afin de ne pas rompre la confiance, ce mécanisme doit être loyale, c’est à dire public, transparent et vérifiable.
D’un point de vue pratique, la mise en place comprend deux parties.
Il faut commencer par recenser les entités éligibles comme autorités de recouvrement. Pour l’instant dans le code de la librairie en php, la liste de ces entités est renvoyée vide. Les applications peuvent donc commencer à prendre en compte ces entités pour l’affichage public. C’est le cas dans klicty mais pas encore dans sylabe.
Il faut ensuite, lors de la protection d’un objet ou de la dissimulation d’un lien, dupliquer la protection ou le lien pour chacune des entités de recouvrement. Cela revient simplement à faire un partage de la protection pour un objet protégé en duplicant le lien de type k de chiffrement de la clé de session.
Pour terminer, la librairie n’intégrera pas par défaut d’entité de recouvrement. Si des entités sont définies comme tel, ce sera uniquement par choix (ou obligation) de l’entité responsable du serveur.
Intégration des groupes dans la librairie php – suite
Suite à l’intégration des groupes dans la librairie php, l’ensemble est fonctionnel et stable dans la librairie ainsi que dans klicty.
Intégration des groupes dans la librairie php
Suite à la définition des groupes, l’intégration a commencé dans la librairie php orienté objet.
L’intégration est profonde puisque les groupes sont gérés comme des objets spécifiques comme c’était déjà le cas pour les entités. Une classe dédiée ainsi que tout un tas de fonctions leurs sont dédiés et personnalisés.
Les applications sylabe et klicty vont intégrer progressivement les groupes, notamment dans un module adapté.
Dans le même temps, un groupe fermé étant uniquement constitué de liens d’une seule entité (et cela doit être vérifié), le filtre social est en cours de mise en place. Ainsi, il est possible de restreindre la prise en compte des liens suivant ces filtres sociaux :
- self : liens de l’entité ;
- strict : liens de l’entité et des entités autorités locales ;
- all : toutes les entités, mais avec un classement par pondération des entités.
L’activation du filtre social et donc de la possibilité de le choisir dans le code à nécessité un revue de tout le code de la librairie et des applications. Il reste à vérifier les modules de sylabe.
Définition des groupes
Dans le cadre de la recherche sur l’implémentation des groupes dans nebule, voir 1 2 3 4 5, deux nouveaux objets réservés ont été ajoutés :
nebule/objet/groupenebule/objet/groupe/ferme
Le groupe
Il a été décidé de rattacher explicitement le groupe aux objets, et donc aussi aux entités notamment. Mais la notion de groupe peut être vu comme plus globale.
Si on reprend par exemple l’objet réservé nebule/danger, les objets qui lui sont liés deviennent de fait un groupe des objets à éviter. Il suffit donc de lier un objet à un autre objet pour créer un groupe. Cependant cela n’est pas très pratique puisque l’on ne peut rechercher que des groupes pré-définis à l’avance et communément acceptés. Cela marche bien pour quelques groupes avec des fonctions biens précises et universellement reconnues, et pas plus.
Fondamentalement, le groupe est la définition d’un ensemble de plusieurs objets. C’est à dire, c’est le regroupement d’au moins deux objets. Le lien peut donc à ce titre être vu comme la matérialisation d’un groupe. Le groupe met en relation des objets vis-à-vis d’une référence. C’est la référence qui identifie le groupe. Dans le cas de notre objet réservé nebule/danger, c’est cet objet réservé qui est la référence du groupe. Par simplification, l’objet de référence peut être assimilé comme étant le groupe.
Tout objet peut ainsi devenir la référence d’un groupe. Cela n’est pas sans poser un gros problème pratique. Puisque tout objet peut être un groupe, comment fait-on pour s’y retrouver dans l’immensité des groupes disponibles ?
Pour simplifier le problème, nous allons considérer les liens comme étant des groupes directs ou explicites. Et nous allons considérer les relations de deux liens ou plus comme étant des groupes indirectes ou implicites. Ces groupes indirectes sont centrés sur un et un seul objet de référence. Si nous prenons par exemple comme référence l’objet réservé nebule/objet/type, nous avons un groupe indirecte qui va contenir tous les objets de même type mime.
Nous allons à partir de maintenant considérer comme groupe uniquement les groupes indirectes.
Mais cela fait encore beaucoup trop de possibilités en pratique pour que la notion de groupe n’ai un intérêt pour gérer les objets. Nous allons en plus restreindre la notion du groupe, et donc son exploitation dans nebule, à l’objet vers lequel un lien explicite est créé avec les objets. Ce lien explicite est un lien de type l avec comme objet meta l’objet réservé nebule/objet/groupe ou nebule/objet/groupe/ferme.
Groupe ouvert ou fermé
L’exploitation des objets d’un groupe nécessite de pouvoir lire et vérifier les liens qui unissent les objets au groupe. Ces liens peuvent être générés par différentes entités, le traitement social des liens déterminera pour une entité donnée quels sont les objets reconnus dans le groupe ou pas. Ce processus est avant tout un traitement pour reconnaitre ou non les objets d’un groupe ouvert.
Pour un groupe fermé, la reconnaissance des objets du groupe n’est plus déterminée par le traitement social des liens. Ne sont reconnus les objets comme appartenant au groupe fermé que ceux dont le lien est signé par l’entité qui a créé le groupe. Dans le cas d’un groupe fermé, les liens générés par une autre entité pour ajouter des objets au groupe ne sont pas pris en compte.
Si il est possible de créer un groupe ouvert avec un objet de référence donné, le même objet de référence peut aussi servir pour un groupe fermé. Dans ce cas, lors du traitement, le groupe ouvert et le groupe fermé apparaissent comme deux groupes distincts. Si plusieurs entités créent des groupes ouverts avec le même objet de référence, un seul groupe est affiché et regroupe tous les groupes ouverts. Si plusieurs entités créent des groupes fermés avec le même objet de référence, il faut exploiter et afficher tous les groupes fermés comme des groupes indépendants.
Un groupe fermé doit toujours être accompagné son l’entité créatrice lors de l’affichage.
Groupe public ou privé
La distinction entre un groupe public et un groupe privé, c’est la visibilité de celui-ci pour les entités tierces. Si tous les liens qui relient les objets au groupe sont dissimulés, alors le groupe est privé et seuls les entités qui peuvent voir ces liens ont accès au groupe.
Cependant, si une partie des liens ne sont pas dissimulés ou si ils sont rendus publics, alors le groupe devient partiellement public.
Les liens, même dissimulés, sont complètement manipulables par toute entité qui y a accès, ainsi en terme de sécurité on peut dire qu’un groupe privé est un groupe public qui s’ignore. Mais ce n’est pas forcément un problème, si une entité A crée un groupe fermé et privé, alors le fait qu’une autre entité B crée un même groupe (même référence) ouvert et public ne rend pas pour autant public le groupe de l’entité A.
Groupe actif ou passif
Un groupe est par défaut passif. Il devient actif lorsqu’il devient capable de réaliser des actions, c’est à dire de signer des liens. Le seul objet capable de signer un lien est une entité, ainsi un groupe actif est un groupe dont l’objet de référence est une entité.
Si le secret de cette entité de référence du groupe n’est connu que d’une seule autre entité (entité maitresse) alors c’est un groupe actif fermé. Si cette entité de référence du groupe a plusieurs entités maitresses alors c’est un groupe actif ouvert.
Un groupe actif ouvert peut aussi être privé si tous ses liens sont dissimulés. Il devient semi-public ou public si une des entités maitresse dévoile tout ou partie des liens du groupe. De la même façon, une entité peut ajouter d’autres entités au groupe, c’est à dire partager le secret de l’entité de référence du groupe. En terme de sécurité, un groupe actif ouvert privé est souvent un groupe actif ouvert public qui s’ignore.
De fait, toute entité piratée devient un groupe actif ouvert, même si le secret de l’entité n’est pas rendu public.
Groupe d’entités
Un groupe d’entité est un groupe dans lequel on ne considère que les objets qui sont des entités. Les autres objets sont ignorés. Lorsque ce groupe n’est plus vu comme un groupe d’entités, tous les objets sont pris en compte et les entités sont gérés comme des objets. La distinction se fait donc uniquement sur le type d’objet que l’on attend du groupe au moment de l’exploiter.
Graphe de groupes
Lorsque l’on a un groupe qui est lié à un autre groupe, comme doit-on l’interpréter ?
Cela crée un graphe de groupes. Il est possible soit d’ignorer les sous-groupes dans un groupe ou au contraire de résoudre le graphe pour en exploiter tous les objets. Dans le cas de la résolution du graphe, on retombe sur les problèmes classiques de la résolution d’un graphe.
Le graphe de groupe peut aussi dans certains cas avoir un traitement convenu. Cela peut être appliqué à la gestion des options ou des droits dans une application. On va ainsi lier des groupes d’entités avec des groupes d’options et/ou des groupes de droits. Dans ce cas on ne parcours le graphe que de façon simple et non ambigüe.
NÅ“ud
La notion de nÅ“ud est concurrente de la notion de groupe. Sauf usage nouveau et différencié, le nÅ“ud va disparaitre de nebule.
Cosignature – orientation
Dans la continuité de la réflexion sur la cosignature et suite.
Une des possibilités que doit permettre la cosignature, c’est que l’on puisse créer une signature (ou assimilé) valide alors que les différentes personnes (et leurs entités) ne sont pas réunies en même temps au même endroit pour réaliser cette signature commune.
Le système classique pour résoudre la cosignature consiste en la répartition du secret suivant le schéma de seuil de Shamir.
Cette solution de partage du secret n’est pas suffisante pour deux raisons.
Pour commencer, cela veut dire que l’on n’a toujours qu’un seul secret mais qu’il est répartit, dilué, entre plusieurs entités. Lorsque l’on veut faire une signature, il faut réunir un minimum de ces entités au même endroit pour accéder au secret qui permettra la signature. A ce moment, le secret est extrêmement vulnérable.
Il faut réaliser une sorte de cérémonie des clés pour cela.
Enfin, la génération du secret est réalisé par un seul équipement et ensuite répartit. Il faut ici aussi une cérémonie des clés avec tous les porteurs d’une partie du secret. Si il n’est pas possible de réunir tout le monde, une partie du secret doit être transmis de façon sür vers le porteur concerné. Mais il ne peut pas dans ce cas garantir par lui-même que personne n’a copié sa partie du secret. Et surtout il ne peut garantir que personne n’a volé le secret complet lors de la cérémonie des clés.
Donc, il faut que chaque porteur génère sa partie de clé, on génère un bi-clé qu’il garde, et dont il peut garantir la confidentialité. Ensuite, il reste à réaliser le mécanisme intermédiaire qui permet, en ne connaissant que les clés publiques des porteurs, de valider une pseudo signature réalisée par chacun des porteurs. Une pseudo signature qui n’impose une présence ni spatial ni temporelle des porteurs.
Liens :
– https://fr.wikipedia.org/wiki/Partage_de_cl%C3%A9_secr%C3%A8te_de_Shamir
– http://www.kilomaths.com/2010/07/partage-de-secret/
Cosignature – suite
Suite de l’article sur la Cosignature.
La notion de groupe est intéressante puisque pour l’instant, si le groupe a été définit dans sa ou ses formes, il n’a pas été définit dans son implémentation.
Cette implémentation peut rejoindre la notion de cosignature. En étendant la notion d’entité à autre chose que des bi-clés cryptographiques, notamment à un fichier de description du groupe et de la validité de sa signature (équivalente), on crée implicitement un groupe. Ce groupe hérite de par ses propriétés internes d’une capacité de signature et de vérification. Comme ce n’est pas un bi-clé cryptographique, il n’y a pas d’objet de clé privée. L’objet définissant le groupe n’est pas suffisant en lui-même pour signer des liens, il doit se reposer sur les ‘vraies’ entités qui composent le groupe.
Par exemple, la forme du fichier définissant un groupe de 3 entités peut être un objet contenant :
[Members] 88848d09edc416e443ce1491753c75d75d7d8790c1253becf9a2191ac369f4ea 01351dd781453092d99377d94990da9bf220c85c43737674a257b525f6566fb4 19762515dd804577f9fd8c005a7803ddee413f264319748e30aa2aedf318ca57 [Signe] (88848d09edc416e443ce1491753c75d75d7d8790c1253becf9a2191ac369f4ea . 01351dd781453092d99377d94990da9bf220c85c43737674a257b525f6566fb4) + (19762515dd804577f9fd8c005a7803ddee413f264319748e30aa2aedf318ca57 . 88848d09edc416e443ce1491753c75d75d7d8790c1253becf9a2191ac369f4ea) + (01351dd781453092d99377d94990da9bf220c85c43737674a257b525f6566fb4 . 19762515dd804577f9fd8c005a7803ddee413f264319748e30aa2aedf318ca57) [Timestamp] 2015-05-28T22:20:13+0200
La signification du groupe, c’est que les membres sont 3 et que la signature d’un lien par deux des trois entités est valide comme étant celle du groupe ( (1 et 2) ou (2 et 3) ou (3 et 1) ).
Ce n’est qu’un exemple…
Cosignature
Une réflexion depuis quelques temps porte sur la cosignature (cf Les entités et le code / Redéfinition de puppetmaster). Et elle est toujours d’actualité. Le but est de permettre d’avoir une entité unique mais dont la clé privée soit répartie en plusieurs morceaux, chaque morceau sous la responsabilité d’une personne différente. On doit avoir plusieurs entités qui peuvent communément, et non individuellement, signer pour l’entité unique.
Le problème peux être résolu en ayant un mécanisme qui valide la signature de l’entité unique par la présence d’un nombre pré-définit de signatures d’entités pré-validées. On n’a plus dans ce cas une entité mais un groupe d’entités dont la cosignature est reconnue comme signature du groupe. Dans ce cas, la notion d’entité s’étend et ne sous-entend plus seulement un objet avec une clé cryptographique mais un objet qui constitue un groupe d’entités avec des règles de fonctionnement.
Jusqu’ici, je n’ai trouvé que des solutions matériels avec un seul bi-clé cryptographique conservé dans une puce et dont l’usage est contraint par l’authentification de plusieurs personnes physiques. Ce n’est pas satisfaisant puisque toutes les personnes doivent être présentes au même endroit au même moment pour activer la clé privée. Les solutions de cosignatures que j’ai trouvé se contentent de gérer de multiples signatures d’un document mais sans gérer cette notion de communauté.
Nommage multiple et protéiforme
Dans nebule, les objets ont forcément un identifiant. Ils ont aussi parfois un nom. Typiquement, c’est le cas lorsque l’objet a pour source un fichier nébulisé.
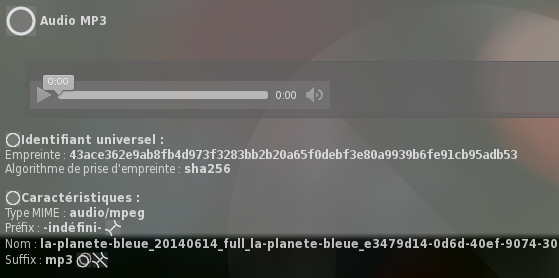
Le nom est un texte de caractères compréhensible par les humains. Déjà, en fonction des langues, il se peux que ce texte ne soit pas compréhensible pas tout le monde. Mais on exclut déjà par principe les caractères non imprimables, même si en réalité ça n’a pas beaucoup d’importance. Il vaut mieux que le texte n’ai pas de retour à la ligne, mais ça peut être interprété, traduit et pris en compte à l’affichage.
Pour un fichier, le nom (qui inclus le chemin) a deux rôles :
- le classement sommaire par sujets en fonction du chemin et parfois du nom ;
- la description sommaire du contenu, un peu comme un titre.
Dans nebule, le nom que l’on peut donner à un objet a le même rôle que le nom pour un fichier. Il donne un titre à l’objet. Par contre, le classement des objets intervient peu avec le nom que ceux-ci pourraient avoir. Ce serait plutôt le rôle de groupes et de nÅ“uds, concept encore en cours d’affinement. Pour un objet, lui donner un nom c’est le lier à un autre objet qui contient le nom avec un lien de type l.
Si un fichier ne peut avoir qu’un seul nom, un objet peut en avoir plus. Il est possible de créer plusieurs liens vers différents objets à utiliser comme noms. Les propriétés de liens multiples et concurrents sont valables aussi pour le nommage.
Lors de l’affichage, comme dans l’exemple ci-dessus, il faut faire un choix. Soit on affiche tous les noms, ce qui peut rapidement devenir problématique et difficilement compréhensible par l’utilisateur. Soit on affiche qu’un seul nom, celui affiché étant celui qui a le plus grand score dans le calcul des relations sociales. C’est cette dernière solution qui est adoptée aujourd’hui.
Mais on peut faire encore mieux. Rien n’interdit un lien pour un titre de renvoyer vers une image. D’ailleurs, ce peut être tout objet sans distinction. C’est l’interprétation du titre qui ici prend son importance. Si on n’interprète que du texte alphanumérique sur une seule ligne, les autres objets seront ignorés comme titre.
Si on décide de prendre en compte aussi les images, il ne sera peut-être pas opportun d’utiliser une image de grande résolution, lourde. On peut utiliser à la place les miniatures, des images dérivées, pour l’affichage comme titre. Les miniatures d’images seront d’ailleurs très régulièrement utilisées lors de l’affichage.
Pour un film, on va peut-être utiliser soit une image fixe soit une petite séquence animée, l’une comme l’autre extraite du film.
L’affichage final peut dans certains cas prendre en compte simultanément plusieurs objets titres mais de types différents. Par exemple accepter une image et un texte, ou un morceau de film, un son et un texte…
Protéiforme ne veut pas dire en forme de protéine mais bien de formes multiples.
Tout est question d’interprétation et de stratégie d’affichage. Tout est possible, aussi.
Dans sylabe, comme dans nebule, une entité a un nom constitué d’un petit texte, un prénom et même un préfixe sur le même principe. Mais elle peut aussi depuis peu avoir une image, typiquement une photo d’identité. Le nommage multiple et protéiforme existe donc déjà.