L’étude de la structure de liens à quatre champs objets (quoi quatre champs) crée un parallèle avec la structure du RDF et le bloc des blockchains.
La possibilité de permettre plus de trois champs dans la partie registre du lien crée de nouvelle possibilités certes à la marge mais qui peuvent avoir une utilité. Le premier est d’apporter un contexte à une opération entre source et destination. D’ailleurs, le champ méta devrait s’appeler opérateur. Et comme une opération peut avoir plusieurs contextes possibles le nombre de champs peut dépasser 4. Il faut cependant mettre une limite aux nombres de champs acceptables dans un lien.
signature_signataire_date_action_source_cible_opération_contexte
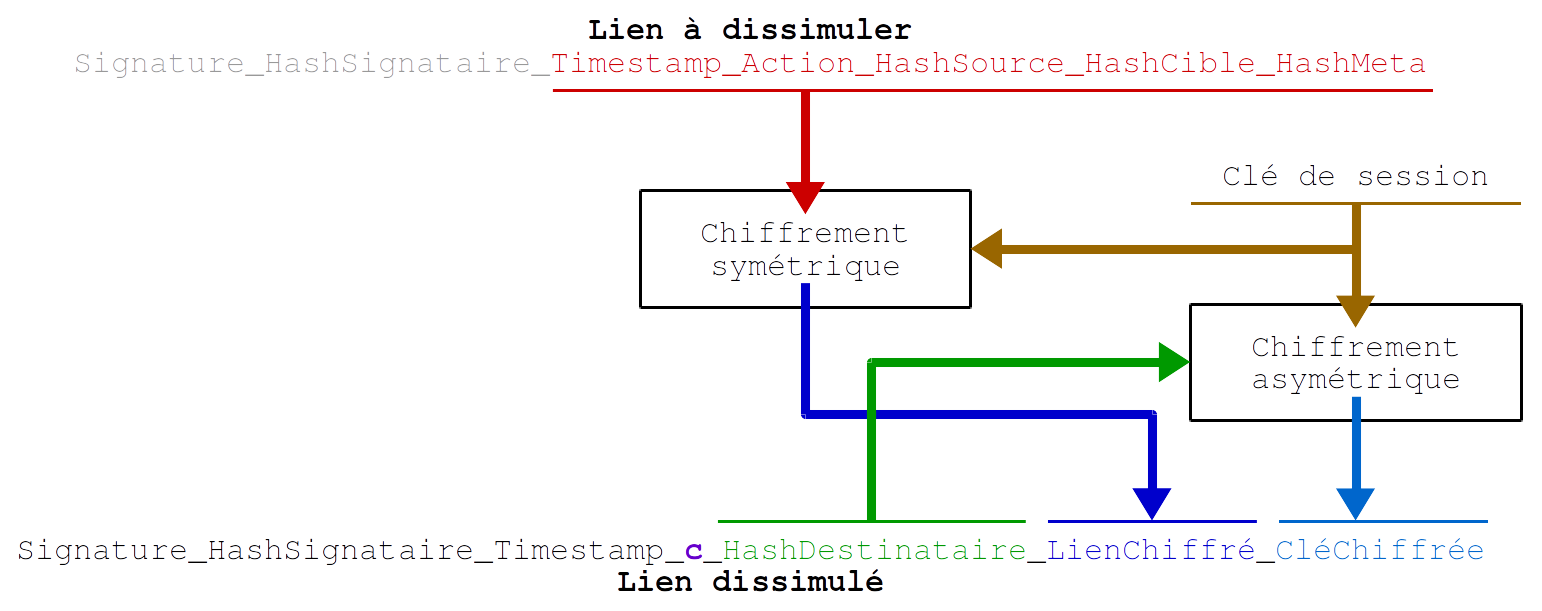
Mais plutôt que d’ajouter des champs, ou en plus, il est possible de prévoir de gérer deux registres de liens dans un même lien. Voir d’en gérer beaucoup plus. On s’approche là de la mise en forme d’un bloc chère aux crypto-monnaies. Dans cette forme, une partie commune contient la signature et la référence de temps. L’action doit rester associé au cÅ“ur du registre de lien. L’action permet aussi de marque un lien dissimulé et donc de le traiter comme tel. Cela nécessite de modifier la forme du lien
signature_signataire_date/action_source_cible_opération_contexte/action_source_cible_opération_contexte
Sous cette forme nous pouvons rejoindre la forme RDF en permettant la réutilisation de champs par indexation. Par exemple lien second cÅ“ur de lien peut référencer les objets 1 et 2, ou 1 et 4 du premier cÅ“ur de lien. Cela abrège l’écriture, prend moins de place mais complexifie la lecture.
signature_signataire_date/action_source_cible_opération/action_2_1_opération
signature_signataire_date/action_source_cible_opération_contexte/action_1_cible_opération_4
Une autre approche est de mieux délimiter le cÅ“ur de lien afin d’ajouter d’autres informations autour. Il n’y a pas une grande quantité d’information à ajouter, ce peut être de multiples signatures, notamment dans un système de cosignature à seuil. Et, à force d’ajouter des choses dans l’enregistrement des liens, il devient utile de placer une version. Les propriétés exploitables du lien seront directement liées à la version donnée. On arrive ainsi à trois types de blocs dans un lien : la version, les registres de liens et les signatures. Là encore la forme du lien enregistré se complexifie pour permettre de retrouver toutes ces parties sans ambiguïté. Et notamment, chaque partie doit être identifiée avec un préfixe, sauf la version si elle est placé avant le reste. La partie horodatage quand à elle doit aussi faire partie de ce qui est signé, dont elle migre vers les cÅ“urs de liens.
(version)(lien/date_action_source_cible_opération)(lien/date_action_source_cible_opération_contexte/action_1_cible_opération_4)(signe/signature_signataire)(signe/signature_signataire)
Il faut cependant veiller à la défendabilité de la structure ainsi créée. Les signatures sont indépendantes les unes des autres et chaque signature doit couvrir la version et tous les cÅ“urs de liens pris dans le même ordre. Jusque là la vérification des liens se faisait après reconstitution de chaque champs et nettoyage afin d’éviter une tentative de contournement. Ce nettoyage préliminaire peut être maintenu même si il sera plus gourmand en temps de calcul.
Cette forme apporte un nouvel intérêt. Puisque les signatures sont séparée, elles deviennent dissociables. Cela veut dire que l’on peut fusionner plusieurs liens identiques mais avec des signataires différents et donc gagner en place.