Il y a déjà une série d’articles en 2012 sur la Liaison secrète (et suite), puis en 2014 sur l’Anonymisation de lien (et correction du registre de lien), et enfin en 2015 sur la Dissimulation de liens, multi-entités et anonymat et l’Exploitation de liens dissimulés.
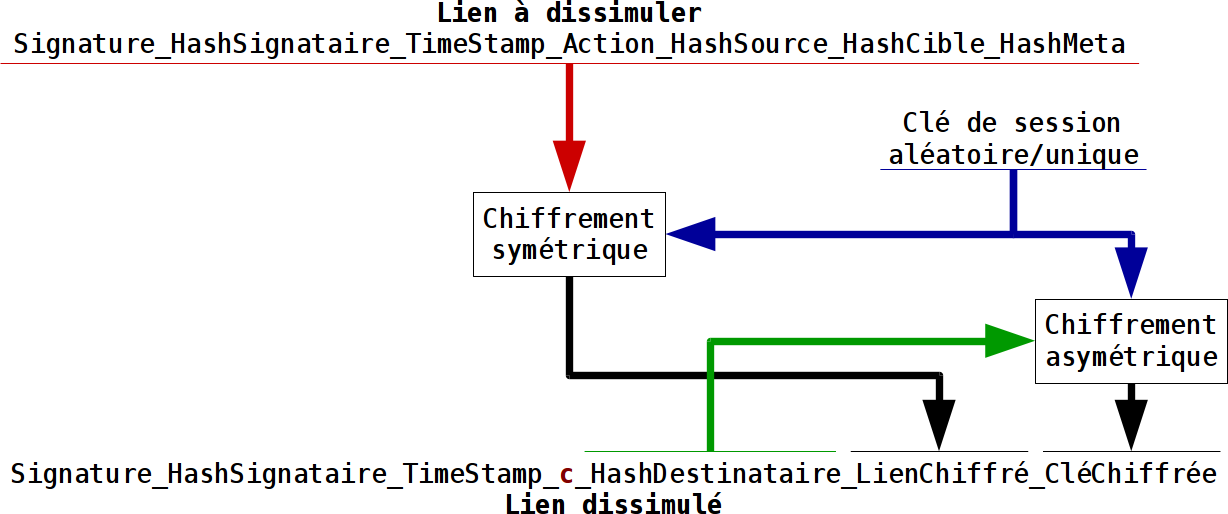
On trouve dès 2015 un schéma d’implémentation d’un lien dissimulé (offusqué) et le mécanisme cryptographique utilisé :
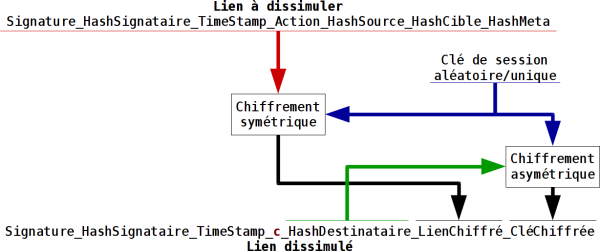
Mais la mise en pratique ne suit pas alors que la bibliothèque nebule en php orienté objet est prête à reconnaître les liens dissimulés.
Parce qu’en pratique, il ne suffit pas juste de générer ces liens et de les lire, il faut aussi les stocker de manière à pouvoir les retrouver tout en gardant des performances acceptables lors du passage à l’échelle.
Comme l’anonymisation attendue nécessite la mise en place d’un minimum de déception vis-à-vis d’un adversaire, il n’est pas possible de stocker les liens dissimulés dans les liens des objets concernés. Cela casserait presque immédiatement la confidentialité du lien dissimulé parce que les objets ont souvent chacun des rôles propres et donc des places privilégiées dans les liens qui servent aux usages de ces objets.
Les deux seules informations que l’on ne peut dissimuler sans bloquer le transfert et l’exploitation des liens dissimulés, c’est l’entité signataire et l’entité destinataire (si différente). Donc le stockage ne peut se faire que de façon connexe à des deux entités. Si ce n’est pas le cas les liens ne pourront pas être retrouvés et utilisés lorsque nécessaire.
Prenons le cas d’une entité qui décide de dissimuler la grande majorité de son activité, elle va donc dissimuler tous les liens qu’elle génère (ou presque). Là où habituellement le stockage des liens aurait été réparti entre tous les objets concernés, du fait de la dissimulation ils vont tous se retrouver attachés à un même objet, l’entité signataire. Cela veut dire que pour extraire un lien de cette entité il va falloir parcourir tous les liens. Cela peut fortement impacter les performances de l’ensemble.
Et c’est aussi sans compter le problème de distribution des liens parce que l’on les distribue aujourd’hui que vers les objets source, cible et méta… et non sur les entités signataires. L’entité destinataire est dans ce cas naturellement desservie directement, est-ce un problème si l’entité signataire ne l’est pas ?
Une autre méthode pourrait consister à créer un objet de référence rattaché à l’entité et spécifiquement dédié à recevoir les liens dissimulés. Mais les liens dissimulés ne contenant pas cette objet de référence, on doit créer un processus plus complexe pour la distribution des liens tenant compte des entités signataires et destinataires.
On peut aussi mettre tous les liens chiffrés dans les liens d’un objet c puisque c’est le type de lien après dissimulation. Mais cela veut dire que tous les liens dissimulés de toutes les entités se retrouvent au même endroit. On ne fait que déplacer le problème de la longue liste des liens à parcourir.
Enfin on peut rester sur une des premières idées qui consiste à stocker des liens dissimulés non plus dans la partie du stockage dédié au liens mais directement dans un objet. Le défaut de cette méthode est qu’à chaque nouveau lien dissimulé généré, il faut refaire un nouvel objet avec une novelle empreinte… et donc un nouveau lien pour le retrouver.
On rejoint le problème de la persistance des données dans le temps, de leurs objets et liens associés. Une solution déjà proposée, mais non implémentée, consiste à organiser un nettoyage par l’oubli des objets et des liens dans le temps en fonction d’une pondération.
Pour commencer à expérimenter, les liens dissimulés seront stockés uniquement avec l’entité destinataire. Cela ne remet pas en cause la distribution actuelle des liens. On verra à l’expérience comment gérer un flux massif de liens et son impact sur les performances.