Cette page contient la documentation technique de nebule version 1.3 .
F / Fondations
Le but du projet nebule, c’est le moteur de gestion des objets. La couche basse qui s’occupe du stockage des objets et liens, et de leur diffusion.
L’interface utilisateur est un programme utilisé pour manipuler ces objets et traduire les liens à l’utilisateur ou les actions de l’utilisateur en liens.
Le projet nebule se concrétise numériquement par trois piliers de base :
- l’objet
- le lien
- la confiance
O / Objet
L’objet est un agglomérat de données numériques.
Un objet numérique est identifié par une empreinte ou condensat (hash). Cette empreinte doit avoir des caractéristiques propres forte correspondant à des fonctions de prise d’empreinte (hash) cryptographiques. C’est à dire :
- L’espace des valeurs possibles est suffisamment grand.
- La répartition des valeurs possibles est équiprobable.
- La résistance aux collisions est forte.
- La fonction utilisée est non réversible.
La fonction de prise d’empreinte actuellement recommandée est sha256. Elle remplie toutes les exigences évoquées ci-dessus. Aucune faille ne permet de remettre en question de façon significative sa résistance et sa non-réversibilité à cours terme.
Pour certains petits besoins spécifiques, la fonction de prise d’empreinte peut être minimaliste, donc rapide et non sécurisée. Cependant, celle-ci doit faire au minimum 2 octets. Les valeurs sur un octets sont susceptibles d’être interprétées, comme la valeur 0 qui ne désigne aucun objet.
…
Définition
L’objet est identifié par un ID égal à la valeur de son empreinte.
L’indication de la fonction de prise d’empreinte (hashage) est impératif. Elle est défini par le lien :
- action :
l - source : ID de l’objet
- cible : hash du nom de l’algorithme de prise d’empreinte
- méta : hash(‘nebule/objet/hash’)
Le lien de définition du type est optionnel. Le type est généralement le type mime reconnu de l’objet.
Caractéristiques optionnelles
Les différentes caractéristiques utilisables :
- nebule/objet
- nebule/objet/hash
- nebule/objet/homomorphe
- nebule/objet/type
- nebule/objet/localisation
- nebule/objet/taille
- nebule/objet/prenom
- nebule/objet/nom
- nebule/objet/surnom
- nebule/objet/prefix
- nebule/objet/suffix
- nebule/objet/liens
- nebule/objet/date
- nebule/objet/date/annee
- nebule/objet/date/mois
- nebule/objet/date/jour
- nebule/objet/date/heure
- nebule/objet/date/minute
- nebule/objet/date/seconde
- nebule/objet/date/zone
- nebule/objet/entite
- nebule/objet/entite/type
- nebule/objet/entite/localisation
- nebule/objet/entite/suivi
- nebule/objet/entite/suivi/seconde
- nebule/objet/entite/suivi/minute
- nebule/objet/entite/suivi/heure
- nebule/objet/entite/suivi/jour
- nebule/objet/entite/suivi/semaine
- nebule/objet/entite/suivi/mois
- nebule/objet/entite/suivi/annee
- nebule/objet/entite/maitre/securite
- nebule/objet/entite/maitre/code
- nebule/objet/entite/maitre/annuaire
- nebule/objet/entite/maitre/temps
- nebule/objet/entite/web
- nebule/objet/entite/web/applications
- nebule/objet/noeud
- nebule/objet/emotion
- nebule/objet/emotion/joie
- nebule/objet/emotion/confiance
- nebule/objet/emotion/peur
- nebule/objet/emotion/surprise
- nebule/objet/emotion/tristesse
- nebule/objet/emotion/degout
- nebule/objet/emotion/colere
- nebule/objet/emotion/interet
- nebule/objet/conversation
- nebule/objet/conversation/ferme
- nebule/objet/conversation/protegee
- nebule/objet/conversation/dissimulee
- nebule/objet/groupe
- nebule/objet/groupe/ferme
- nebule/danger
- nebule/warning
- nebule/arborescence
Une caractéristique d’un objet est défini par le lien :
- action :
l - source : ID de l’objet
- cible : hash de la valeur de la caractéristique (ex : ‘Dupont’)
- méta : hash de la caractéristique (ex : ‘
nebule/objet/nom‘)
Cette liste est susceptible de s’agrandir avec le temps pour répondre à de nouveaux besoins…
Nommage
Le nommage à l’affichage du nom des objets repose sur plusieurs propriétés :
- nom
- prénom
- surnom
- préfixe
- suffixe
Ces propriétés sont matérialisées par des liens de type l avec comme objets méta, respectivement :
nebule/objet/nomnebule/objet/prenomnebule/objet/surnomnebule/objet/prefixnebule/objet/suffix
Par convention, voici le nommage des objets pour l’affichage :
prénom préfixe/nom.suffixe surnom- action :
l - source : ID de l’objet
- cible : hash de la valeur de nommage (ex : ‘Dupont’)
- méta : hash propriété de nommage (ex : ‘
nebule/objet/nom‘)
OG / Groupe
Le groupe est un objet définit comme tel, c’est à dire qu’il doit avoir un type mime nebule/objet/groupe.
Fondamentalement, le groupe est un ensemble de plusieurs objets. C’est à dire, c’est le regroupement d’au moins deux objets. Le lien peut donc à ce titre être vu comme la matérialisation d’un groupe. Mais la définition du groupe doit être plus restrictive afin que celui-ci soit utilisable. Pour cela, dans nebule, le groupe n’est reconnu comme tel uniquement si il est marqué de son type mime. Il est cependant possible d’instancier explicitement un objet comme groupe et de l’utiliser comme tel en cas de besoin.
Le groupe va permettre de regrouper, et donc d’associer et de retrouver, des objets. L’objet du groupe va avoir des liens vers d’autres objets afin de les définir comme membres du groupe.
Un groupe peut avoir des liens de membres vers des objets définis aussi comme groupes. Ces objets peuvent être vus comme des sous-groupes. La bibliothèque nebule ne prend en compte qu’un seul niveau de groupe, c’est à dire que les sous-groupes sont gérés simplement comme des objets.
OGO / Objet
L’objet du groupe peut être de deux natures.
Soit c’est un objet existant qui est en plus définit comme un groupe. L’objet peut avoir un contenu et a sürement d’autres types mime propres. Dans ce cas l’identifiant de groupe est l’identifiant de l’objet utilisé.
Soit c’est un objet dit virtuel qui n’a pas et n’aura jamais de contenu. Cela n’empêche pas qu’il puisse avoir d’autres types mime. Dans ce cas l’identifiant de groupe a une forme commune aux objets virtuels.
La création d’un objet virtuel comme groupe se fait en créant pour identifiant la concaténation d’un hash (sha256) d’une valeur aléatoire de 128bits et de la chaîne 006e6562756c652f6f626a65742f67726f757065. Soit un identifiant complet de la taille de 102 caractères.
OGN / Nommage
Le nommage à l’affichage du nom des groupes repose sur une seule propriété :
- nom
Cette propriété est matérialisée par un lien de type l avec comme objets méta :
nebule/objet/nom
Par convention, voici le nommage des groupes :
nom
OGP / Protection
En tant que tel le groupe ne nécessite pas de protection puisque soit l’objet du groupe n’a pas de contenu soit on n’utilise pas son contenu directement.
La gestion de la protection est désactivée dans une instance de groupe.
OGD / Dissimulation
Le groupe peut en tant que tel être dissimulé, c’est à dire que l’on dissimule l’existence du groupe, donc sa création.
La dissimulation devrait se faire lors de la création du groupe.
L’annulation de la dissimulation d’un groupe revient à révéler le lien de création du groupe.
La dissimulation peut se (re)faire après la création du groupe mais son efficacité est incertaine si les liens de création ont déjà été diffusés. En cas de dissimulation à posteriori, il faut générer un lien de suppression du groupe puis générer un nouveau lien dissimulé de création du groupe à une date postérieure au lien de suppression.
OGF / Fermeture
Le groupe va contenir un certain nombre de membres ajouter par différentes entités. Il est possible de limiter le nombre des membres à utiliser dans un groupe en restreignant artificiellement les entités contributrices du groupe. Ainsi on marque le groupe comme fermé et on filtre sur les membres uniquement ajoutés par des entités définies.
Dans nebule, l’objet réservé nebule/objet/groupe/ferme est dédié à la gestion des groupes fermés. Un groupe est considéré fermé quand on a l’objet réservé en champs méta, l’entité en cours en champs cible et l’ID du groupe en champs source. Si au lieu d’utiliser l’entité en cours pour le champs cible on utilise une autre entité, cela revient à prendre aussi en compte ses liens dans le groupe fermé. Dans ce cas c’est une entité contributrice.
C’est uniquement un affichage du groupe que l’on a et non la suppression de membres du groupe.
Lorsque l’on a marqué un groupe comme fermé, on doit explicitement ajouter des entités que l’on veut voir contribuer.
Il est possible indéfiniment de fermer et ouvrir un groupe.
Il est possible de fermer un groupe qui ne nous appartient afin par exemple de le rendre plus lisible.
Lorsque l’on a marqué un groupe comme fermé, on peut voir la liste des entités explicitement que l’on veut voir contribuer. On peut aussi voir les entités que les autres entités veulent voir contribuer et décider ou non de les ajouter.
Lorsqu’un groupe est marqué comme fermé, l’interface de visualisation du groupe peut permettre de le visualiser temporairement comme un groupe ouvert.
Le traitement des liens de fermeture d’un groupe doit être fait exclusivement avec le traitement social self.
OGPM / Protection des membres
Le groupe va contenir un certain nombre de membres ajouter par différentes entités. Il est possible de limiter la visibilité du contenu des membres utilisés dans un groupe en restreignant artificiellement les entités destinataires qui pourront les consulter.
Dans nebule, l’objet réservé nebule/objet/groupe/protege est dédié à la gestion des groupes protégés. Un groupe est considéré protégé quand on a l’objet réservé en champs méta, l’entité en cours en champs cible et l’ID du groupe en champs source. Si au lieu d’utiliser l’entité en cours pour le champs cible on utilise une autre entité, cela revient à partager aussi les objets protégés créés pour ce groupe. Cela ne repartage pas la protection des objets déjà protégés.
Dans un groupe marqué protégé, tous les nouveaux membres ajoutés au groupe ont leur contenu protégé. Ce n’est valable que pour l’entité en cours et éventuellement celles qui lui font confiance.
Lorsque l’on a marqué un groupe comme protégé, on doit explicitement ajouter des entités avec qui on veut partager les contenus.
Il est possible indéfiniment de protéger et déprotéger un groupe.
Il est possible de protéger un groupe qui ne nous appartient afin de masquer le contenu des membres que l’on y ajoute.
Lorsque l’on a marqué un groupe comme protégé, on peut voir la liste des entités explicitement a qui on veut partager les contenus. On peut aussi voir les entités a qui les autres entités veulent partager les contenus et décider ou non de les ajouter.
Le traitement des liens de protection d’un groupe doit être fait exclusivement avec le traitement social self.
OGDM / Dissimulation des membres
Le groupe va contenir un certain nombre de membres ajouter par différentes entités. Il est possible de limiter la visibilité de l’appartenance des membres utilisés dans un groupe en restreignant artificiellement les entités destinataires qui pourront les voir.
Dans nebule, l’objet réservé nebule/objet/groupe/dissimule est dédié à la gestion des groupes dissimulés. Un groupe est considéré dissimulé quand on a l’objet réservé en champs méta, l’entité en cours en champs cible et l’ID du groupe en champs source. Si au lieu d’utiliser l’entité en cours pour le champs cible on utilise une autre entité, cela revient à partager aussi les objets dissimulés créés pour ce groupe. Cela ne repartage pas la dissimulation des objets déjà dissimulés.
Dans un groupe marqué dissimulé, tous les nouveaux membres ajoutés au groupe sont dissimulés. Ce n’est valable que pour l’entité en cours et éventuellement celles qui lui font confiance.
Lorsque l’on a marqué un groupe comme dissimulé, on doit explicitement ajouter des entités avec qui on veut partager les membres du groupe.
Il est possible indéfiniment de dissimuler et dé-dissimuler un groupe.
Il est possible de dissimuler un groupe qui ne nous appartient afin de masquer le contenu des membres que l’on y ajoute.
Lorsque l’on a marqué un groupe comme dissimulé, on peut voir la liste des entités explicitement a qui on veut partager les contenus. On peut aussi voir les entités a qui les autres entités veulent partager les contenus et décider ou non de les ajouter.
Le traitement des liens de dissimulation d’un groupe doit être fait exclusivement avec le traitement social self.
OGL / Liens
Une entité doit être déverrouillée pour la création de liens.
Le lien de définition du groupe :
- action :
l - source : ID du groupe
- cible : hash(‘nebule/objet/groupe’)
- méta : hash(‘nebule/objet/type’)
Le lien de suppression d’un groupe :
- action :
x - source : ID du groupe
- cible : hash(‘nebule/objet/groupe’)
- méta : hash(‘nebule/objet/type’)
Le lien de dissimulation d’un groupe est le lien de définition caché dans une lien de type c.
Le lien de rattachement d’un membre du groupe :
- action :
l - source : ID du groupe
- cible :Â ID de l’objet
- méta : ID du groupe
Le lien de suppression de rattachement d’un membre du groupe :
- action :
x - source : ID du groupe
- cible :Â ID de l’objet
- méta : ID du groupe
Le lien de fermeture d’un groupe :
- action :
l - source : ID du groupe
- cible : ID de l’entité, par défaut l’entité signataire.
- méta : hash(‘nebule/objet/groupe/ferme’)
Le lien de suppression de fermeture d’un groupe :
- action :
x - source : ID du groupe
- cible : ID de l’entité, par défaut l’entité signataire.
- méta : hash(‘nebule/objet/groupe/ferme’)
Le lien de protection des membres d’un groupe :
- action :
l - source : ID du groupe
- cible : ID de l’entité, par défaut l’entité signataire.
- méta : hash(‘nebule/objet/groupe/protege’)
Le lien de suppression de protection des membres d’un groupe :
- action :
x - source : ID du groupe
- cible : ID de l’entité, par défaut l’entité signataire.
- méta : hash(‘nebule/objet/groupe/protege’)
Le lien de dissimulation des membres d’un groupe :
- action :
l - source : ID du groupe
- cible : ID de l’entité, par défaut l’entité signataire.
- méta : hash(‘nebule/objet/groupe/dissimule’)
Le lien de suppression de dissimulation des membres d’un groupe :
- action :
x - source : ID du groupe
- cible : ID de l’entité, par défaut l’entité signataire.
- méta : hash(‘nebule/objet/groupe/dissimule’)
OGIV / Implémentation des Variables
Les variables spécifiques aux groupes :
permitWriteGroup: permet toute écriture de groupes.
Les variables qui ont une influence sur les groupes :
permitWrite: permet toute écriture d’objets et de liens ;permitWriteObject: permet toute écriture d’objets ;permitCreateObject: permet la création locale d’objets ;permitWriteLink: permet toute écriture de liens ;permitCreateLink: permet la création locale de liens.
Il est nécessaire à la création d’un groupe de pouvoir écrire des objets comme le nom du groupe, même si l’objet du groupe ne sera pas créé.
OGIA / Implémentation des Actions
Dans les actions, on retrouve les chaînes :
creagrp: Crée un groupe.creagrpnam: Nomme le groupe à créer.creagrpcld: Marque fermé le groupe à créer.creagrpobf: Dissimule les liens du groupe à créer.actdelgrp: Supprime un groupe.actaddtogrp: Ajoute l’objet courant membre à groupe.actremtogrp: Retire l’objet courant membre d’un groupe.actadditogrp: Ajoute un objet membre au groupe courant.actremitogrp: Retire un objet membre du groupe courant.
OGIF / Implémentation des Fonctions
Dans la classe nebule, on trouve :
- La fonction
getListGroupsLinks()retourne la liste des liens définissants les groupes. - La fonction
getListGroupsID()retourne la liste des identifiants des groupes.
Dans la classe Object, on trouve :
- La fonction
getIsGroup()retourne si l’objet est un groupe. - La fonction
getListIsMemberOnGroupLinks()retourne la liste des identifiants des groupes desquels l’objet est membre. - La fonction
getListIsMemberOnGroupID()retourne la liste des identifiants des groupes desquels l’objet est membre.
Dans la classe Group, on trouve :
- La fonction
unsetGroup()supprime la définition du groupe. - La fonction
getMarkClosed()retourne si le groupe est marqué fermé ou si l’entité demandée est contributrice. - La fonction
setMarkClosed()marque le groupe comme fermé ou marque l’entité demandée comme contributrice. - La fonction
unsetMarkClosed()marque le groupe comme ouvert ou retire l’entité demandée comme contributrice. - La fonction
getMarkProtected()retourne si le groupe est marqué protégé (ses membres). - La fonction
setMarkProtected()marque le groupe comme protégé (ses membres). - La fonction
unsetMarkProtected()marque le groupe comme non protégé (ses membres). - La fonction
getMarkObfuscated()retourne si le groupe est marqué dissimulé (ses membres). C’est différent de la dissimulation de la création du groupe. - La fonction
setMarkObfuscated()marque le groupe comme dissimulé (ses membres). - La fonction
unsetMarkObfuscated()marque le groupe comme non dissimulé (ses membres). - La fonction
getIsMember()retourne si un objet est membre du groupe. - La fonction
setMember()ajout un objet comme membre. - La fonction
unsetMember()retire l’objet comme membre. - La fonction
getListMembersLinks()retourne les liens des objets définis comme membres. - La fonction
getListMembersID()retourne les identifiants des objets définis comme membres. - La fonction
getCountMembers()retourne le nombre d’objets définis comme membres.
OC / Conversation
…
OCL / Liens
La conversation est un objet caractéristique. Cet objet est reconnu par son type défini par le lien :
- action :
l - source : ID aléatoire entre 129 et 191 bits
- cible : hash(‘nebule/objet/conversation’)
- méta : hash(‘nebule/objet/type’)
L’indication de la fonction de prise d’empreinte (hashage) est impératif. Le lien est identique à celui défini pour un objet.
Toutes les autres indications sont optionnelles.
OCN / Nommage
Le nommage à l’affichage du nom des groupes repose sur une seule propriété :
- nom
Cette propriété est matérialisée par un lien de type l avec comme objets méta :
nebule/objet/nom
Par convention, voici le nommage des groupes :
nomOE / Entité
…
L’entité est un objet caractéristique. Elle dispose d’une clé publique, par laquelle elle est identifiée, et d’une clé privée.
Définition
L’indication de la fonction de prise d’empreinte (hashage) ainsi que le type de bi-clé sont impératifs. Le lien est identique à celui défini pour un objet.
Le type mime mime-type:application/x-pem-file est suffisant pour indiquer que cet objet est une entité. Des valeurs équivalentes pourront être définies ultérieurement.
Toutes les autres indications sont optionnelles.
OEN / Nommage
Le nommage à l’affichage du nom des entités repose sur plusieurs propriétés :
- nom
- prénom
- surnom
- préfixe
- suffixe
Ces propriétés sont matérialisées par des liens de type l avec comme objets méta, respectivement :
nebule/objet/nomnebule/objet/prenomnebule/objet/surnomnebule/objet/prefixnebule/objet/suffix
Par convention, voici le nommage des entités :
préfixe prénom "surnom" nom suffixeLocalisation
Description
Une localisation permet de trouver l’emplacement des objets et liens générés par une entité.
Un emplacement n’a de sens que pour une entité.
Une entité peut disposer de plusieurs localisations. Il faut considérer que toute entité qui héberge l’objet d’une autre entité devient de fait une localisation valide même si cela n’est pas explicitement définit.
Interface
Description
L’interface est une entité.
…
Application
Description
L’application est une entité.
…
Annuaire
Description
L’annuaire est une entité.
…
Relais
Description
Le relais est une entité.
…
L / Lien
Le lien est la matérialisation dans un graphe d’une relation entre deux objets.
Liens d’un objet
Les liens d’un objet sont consultables séquentiellement. Il doivent être perçus comme des méta-données d’un objet.
Les liens sont séparés soit par un caractère espace » « , soit par un retour chariot « \n ». Un lien est donc une suite de caractères ininterrompue, c’est à dire sans espace ou retour à la ligne.
La taille du lien dépend de la taille de chaque champs.
Chaque localisation contenant des liens doit avoir un entête de version.
Liens dans un objet
Certains liens d’un objet peuvent être contenus dans un autre objet.
Cette forme de stockage des liens permet de les transmettre et de les manipuler sous la forme d’un objet. On peut ainsi profiter du découpage et du chiffrement. Plusieurs liens peuvent être stockés sans être nécessairement en rapport avec les mêmes objets.
Les liens stockés dans un objet ne peuvent pas faire référence à ce même objet.
Tout ajout de lien crée implicitement un nouvel objet de mise à jour, c’est à dire lié par un lien de type u.
Chaque fichier contenant des liens doit avoir un entête de version.
Les objets contenants des liens ne sont pas reconnus et exploités lors de la lecture des liens. Ceux-ci doivent d’abord être extraits et injectés dans les liens des objets concernés. En clair, on ne peux pas s’en servir facilement pour de l’anonymisation.
LE / Entête
L’entête des liens est constitué du texte nebule/liens/version/1.2. Il est séparé du premier lien soit par un caractère espace » « , soit par un retour chariot « \n ».
Il doit être transmit avec les liens, en premier.
LR / Registre
Le registre du lien décrit la syntaxe du lien :
Signature_HashSignataire_TimeStamp_Action_HashSource_HashCible_HashMetaTout lien qui ne respecte pas cette syntaxe est à considérer comme invalide et à supprimer. Tout lien dont la Signature est invalide est à considérer comme invalide et à supprimer. La vérification peut être réalisée en ré-assemblant les champs après nettoyage.
LRSI / Le champ Signature
Le champ Signature est représenté en deux parties séparées par un point « . » . La première partie contient la valeur de la signature. La deuxième partie contient le nom court de la fonction de prise d’empreinte utilisée.
La signature est calculée sur l’empreinte du lien réalisée avec la fonction de prise d’empreinte désignée dans la deuxième partie. L’empreinte du lien est calculée sur tout le lien sauf le champs signature, c’est à dire sur « _HashSignataire_TimeStamp_Action_HashSource_HashCible_HashMeta » avec le premier underscore inclus.
La signature ne contient que des caractères hexadécimaux, c’est à dire de « 0 » à « 9 » et de « a » à « f » en minuscule. La fonction de prise d’empreinte est notée en caractères alpha-numériques en minuscule.
LRHSI / Le champ HashSignataire
Le champ signataire désigne l’objet de l’entité qui génère le lien et le signe.
Il ne contient que des caractères hexadécimaux, c’est à dire de « 0 » à « 9 » et de « a » à « f » en minuscule.
LRT / Le champ TimeStamp
Le champ TimeStamp est une marque de temps qui donne un ordre temporel aux liens. Ce champs peut être une date et une heure au format ISO8601 ou simplement un compteur incrémental.
LRA / Le champ Action
Le champ Action détermine la façon dont le lien doit être utilisé.
Quand on parle du type d’un lien, on fait référence à son champ Action.
L’interprétation de ce champ est limité au premier caractère. Des caractères alpha-numériques supplémentaires sont autorisés mais ignorés.
Cette interprétation est basée sur un vocabulaire particulier. Ce vocabulaire est spécifique à nebule v1.2 (et nebule v1.1).
Le vocabulaire ne reconnaît que les 8 caractères l, f, u, d, e, x, k et s, en minuscule.
LRAL / Action l – Lien entre objets
Met en place une relation entre deux objets. Cette relation a un sens de mise en place et peut être pondérée par un objet méta.
Les liens de type l ne devraient avoir ni HashMeta nul ni HashCible nul.
LRAF / Action f – Dérivé d’objet
Le nouvel objet est considéré comme enfant ou parent suivant le sens du lien.
Le champs ObjetMeta doit être vu comme le contexte du lien. Par exemple, deux objets contenants du texte peuvent être reliés simplement sans contexte, c’est à dire reliés de façon simplement hiérarchique. Ces deux mêmes textes peuvent être plutôt (ou en plus) reliés avec un contexte comme celui d’une discussion dans un blog. Dans ce deuxième cas, la relation entre les deux textes n’a pas de sens en dehors de cette discussion sur ce blog. Il est même probable que le blog n’affichera pas les autres textes en relations si ils n’ont pas un contexte appartenant à ce blog.
f comme fork.
LRAU / Action u – Mise à jour d’objet
Mise à jour d’un objet dérivé qui remplace l’objet parent.
u comme update.
LRAD / Action d – Suppression d’objet
L’objet est marqué comme à supprimer d’un ou de tous ses emplacements de stockage.
d comme delete.
Le champs HashCible peut être nuls, c’est à dire égal à 0. Si non nul, ce champs doit contenir une entité destinataire de l’ordre de suppression. C’est utilisé pour demander à une entité relaie de supprimer un objet spécifique. Cela peut être utilisé pour demander à une entité en règle générale de bien vouloir supprimer l’objet, ce qui n’est pas forcément exécuté.
Le champs HashMeta doit être nuls, c’est à dire égal à 0.
Un lien de suppression sur un objet ne veut pas forcément dire qu’il a été supprimé. Même localement, l’objet est peut-être encore présent. Si le lien de suppression vient d’une autre entité, on ne va sürement pas par défaut en tenir compte.
Lorsque le lien de suppression est généré, le serveur sur lequel est généré le lien doit essayer par défaut de supprimer l’objet. Dans le cas d’un serveur hébergeant plusieurs entités, un objet ne sera pas supprimé si il est encore utilisé par une autre entité, c’est à dire si une entité a un lien qui le concerne et n’a pas de lien de suppression.
LRAE / Action e – Équivalence d’objets
Définit des objets jugés équivalents, et donc interchangeables par exemple pour une traduction.
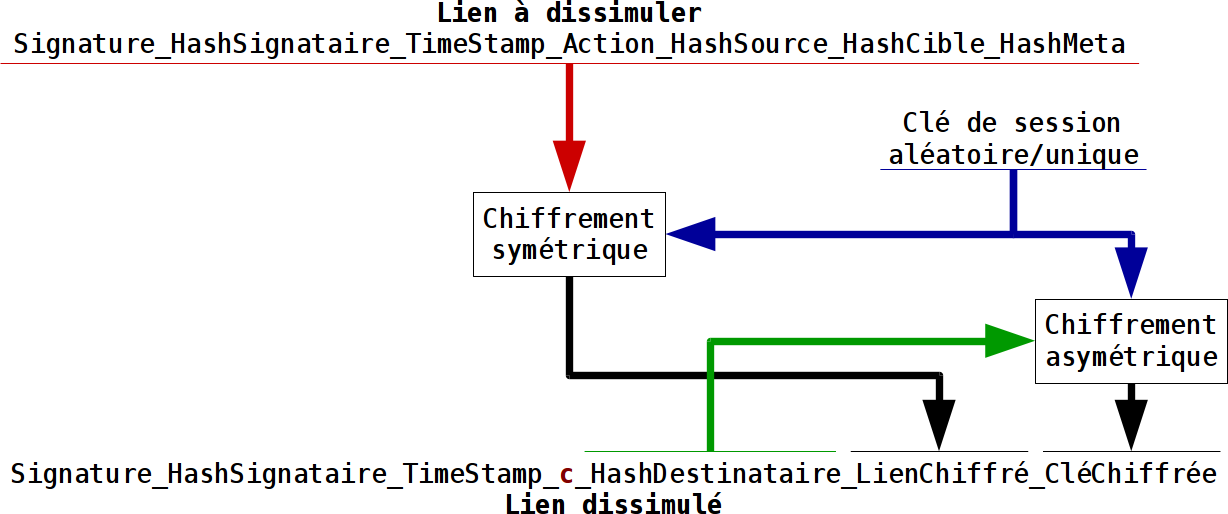
LRAC / Action c – Chiffrement de lien
Ce lien contient un lien chiffré. Il permet d’offusquer des liens entre objets et donc d’anonymiser certaines actions de l’entité.
Le champs HashSource fait référence à l’entité destinataire du lien, celle qui peut le déchiffrer. A part le champs de l’entité signataire, c’est le seul champs qui fait référence à un objet.
Le champs HashCible ne contient pas la référence d’un objet mais le lien chiffré et encodé en hexadécimal. Le chiffrement est de type symétrique avec la clé de session. Le lien offusqué n’a pas grand intérêt en lui même, c’est le lien déchiffré qui en a.
Le champs HashMeta ne contient pas la référence d’un objet mais la clé de chiffrement du lien, dite clé de session. Cette clé est chiffrée (asymétrique) pour l’entité destinataire et encodée en hexadécimal.
Lors du traitement des liens, si une entité est déverrouillée, les liens offusqués pour cette entité doivent être déchiffrés et utilisés en remplacement des liens offusqués originels. Les liens offusqués doivent être vérifiés avant déchiffrement. Les liens déchiffrés doivent être vérifiés avant exploitation.
LRAK / Action k – Chiffrement d’objet
Désigne la version chiffrée de l’objet.
LRAS / Action s – Subdivision d’objet
Désigne un fragment de l’objet.
Ce champ nécessite un objet méta qui précise intervalle de contenu de l’objet d’origine. Le contenu de l’objet méta doit être de la forme x-y avec :
xetyexprimé en octet sans zéro et sans unité ;xstrictement supérieur à zéro ;ystrictement inférieur ou égal à la taille de l’objet (lien vers nebule/objet/taille) ;xinférieur ày;- sans espace, tabulation ou retour chariot.
LRAX / Action x – Suppression de lien
Supprime un ou plusieurs liens précédemment mis en place.
Les liens concernés par la suppression sont les liens antérieurs de type l, f, u, d, e, k et s. Ils sont repérés par les 3 derniers champs, c’est à dire sur HashSource_HashCible_HashMeta. Les champs nuls sont strictement pris en compte.
Le champ TimeStamp permet de déterminer l’antériorité du lien et donc de déterminer sa suppression ou pas.
C’est la seule action sur les liens et non sur les objets.
LRHS / Le champ HashSource
Le champ HashSource désigne l’objet source du lien.
Le champ signataire ne contient que des caractères hexadécimaux, c’est à dire de « 0 » à « 9 » et de « a » à « f » en minuscule.
LRHC / Le champ HashCible
Le champ HashCible désigne l’objet destination du lien.
Le champ signataire ne contient que des caractères hexadécimaux, c’est à dire de « 0 » à « 9 » et de « a » à « f » en minuscule.
Il peut être nuls, c’est à dire représentés par la valeur « 0 » sur un seul caractère.
LRHM / Le champ HashMeta
Le champ HashMeta désigne l’objet contenant une caractérisation du lien entre l’objet source et l’objet destination.
Le champ signataire ne contient que des caractères hexadécimaux, c’est à dire de « 0 » à « 9 » et de « a » à « f » en minuscule.
Il peut être nuls, c’est à dire représentés par la valeur « 0 » sur un seul caractère.
L1 / Lien simple
Le registre du lien simple a ses champs HashCible et HashMeta égaux à « 0 ».
Il ressemble à :
Signature_HashSignataire_TimeStamp_Action_HashSource_0_0L2 / Lien double
Le registre du lien double a son champ HashMeta égal à « 0 ».
Il ressemble à :
Signature_HashSignataire_TimeStamp_Action_HashSource_HashCible_0L3 / Lien triple
Le registre du lien triple est complètement utilisé.
Il ressemble à :
Signature_HashSignataire_TimeStamp_Action_HashSource_HashCible_HashMetaC / Confiance
La confiance n’est pas quelque chose de palpable, même numériquement. Cela tient plus de la façon de concevoir les choses et le fait de faire en sorte que l’ensemble soit solide. L’ensemble doit être cohérent et résistant. On doit pouvoir compter sur ce que l’on a.
La confiance est donc sous-jacente aux objets et aux liens.
Les objets et les liens doivent tous être signés. Toute modification devient impossible si l’on prend le temps de vérifier les signatures.
En l’absence de nouvelle découverte mathématique majeure, les algorithmes cryptographiques nous permettent aujourd’hui une offuscation forte et une prise d’empreinte fiable. C’est le chiffrement et la signature.
CO / La confiance dans l’objet
L’intégrité et la confidentialité des objets est garantie non pas par une méta-donnée mais par les mathématiques qui animent les algorithmes cryptographiques.
L’objet est référencé par une empreinte cryptographique. L’empreinte d’un objet doit être vérifiée lors de la fin de la réception de l’objet. L’empreinte d’un objet devrait être vérifiée avant chaque utilisation de cet objet. Un objet avec une empreinte qui ne lui correspond pas doit être supprimé. Lors de la suppression d’un objet, les liens de cet objet sont conservés.
CL / La confiance dans le lien
L’intégrité des liens est garantie non pas par une méta-donnée mais par les fonctions mathématiques utilisées par les algorithmes cryptographiques.
La signature du lien est obligatoire. La signature doit être réalisée par le signataire. La signature englobe tout le lien à l’exception d’elle-même. Un lien avec une signature invalide ou non vérifiable doit être ignoré et supprimé.
Toute modification de l’un des champs entraîne l’invalidation de tout le lien.
L’empreinte du signataire est inclue dans la partie signée, ainsi il ne peut être modifier sans invalider tout le lien. On ne peut ainsi pas usurper une autre entité.
Fonctionnement
L’objet
…
Le lien
…
L’entité
Une entité est un objet contenant une clé cryptographique publique. Cette clé permet de vérifier les liens signés par cette entité.
Création d’une entité
La première étape consiste en la génération d’un bi-clé (public/privé) cryptographique. Ce bi-clé peut être de type RSA ou équivalent. Aujourd’hui, seul RSA est reconnu.
On extrait la clé publique du bi-clé. Le calcul de l’empreinte cryptographique de la clé publique donne l’identifiant de l’entité. On écrit dans les objets (o/*) l’objet avec comme contenu la clé publique et comme id son empreinte cryptographique.
On extrait la clé privée du bi-clé. Il est fortement conseillé lors de l’extraction de protéger tout de suite la clé privée avec un mot de passe. On écrit dans les objets (o/*) l’objet avec comme contenu la clé privée et comme id son empreinte cryptographique (différente de celle de la clé publique).
A partir de maintenant, le bi-clé n’est plus nécessaire. Il faut la supprimer avec un effacement sécurisé.
Pour que l’objet soit reconnu comme entité il faut créer les liens correspondants.
- Lien 1 :
- Signature du lien par la clé privée de la nouvelle entité ;
- Identifiant de la clé publique ;
- Horodatage ;
- Lien de type
l; - Identifiant de la clé publique ;
- Hash de l’algorithme de hash utilisé pour le calcul des empreintes ;
- Hash de ‘nebule/objet/hash’.
- Lien 2 :
- Signature du lien par la clé privée de la nouvelle entité ;
- Identifiant de la clé publique ;
- Horodatage ;
- Lien de type
l; - Identifiant de la clé privée ;
- Hash de l’algorithme de hash utilisé pour le calcul des empreintes ;
- Hash de ‘nebule/objet/hash’.
- Lien 3 :
- Signature du lien par la clé privée de la nouvelle entité ;
- Identifiant de la clé publique ;
- Horodatage ;
- Lien de type
l; - Identifiant de la clé publique ;
- Hash de ‘application/x-pem-file’.
- Hash de ‘nebule/objet/type’.
- Lien 4 :
- Signature du lien par la clé privée de la nouvelle entité ;
- Identifiant de la clé publique ;
- Horodatage ;
- Lien de type
l; - Identifiant de la clé privée ;
- Hash de ‘application/x-pem-file’.
- Hash de ‘nebule/objet/type’.
- Lien 5 :
- Signature du lien par la clé privée de la nouvelle entité ;
- Identifiant de la clé publique ;
- Horodatage ;
- Lien de type
f; - Identifiant de la clé privée ;
- Identifiant de la clé publique ;
- 0.
C’est le minimum vital pour une entité. Ensuite, d’autres propriétés peuvent être ajoutées à l’entité (id clé publique) comme sont nom, son type, etc…
Si le mot de passe de la clé privée est définit par l’utilisateur demandeur de la nouvelle entité, il faut supprimer ce mot de passe avec un effacement sécurisé.
Si le mot de passe de la clé privée a été généré, donc que la nouvelle entité est esclave d’une entité maître, le mot de passe doit être stocké dans un objet chiffré pour l’entité maître. Et il faut générer un lien reliant l’objet de mot de passe à la clé privée de la nouvelle entité.
Stockage
Support
…
Enregistrement
…
Lecture
…
Échanges
Moyens et supports d’échange
Il est possible de télécharger des objets et des liens avec différents protocoles. Le plus simple étant le http. Le protocole et le serveur distant doivent être capable de transmettre une requête et de renvoyer en sens inverse une réponse.
Côté serveur, c’est à dire la machine qui fait office de relais des objets et liens, tout ne peut pas être demandé. Les requêtes doivent être triviales à traiter, ne pas nécessiter de forte puissance de calcul ni d’empreinte mémoire démesurée. Une avalanche de requêtes diverses ne doit pas mettre à plat le serveur.
…
protocole neb://
Ce protocole sera conçu ultérieurement. Tous les échanges se font actuellement via le protocole http://…
L’ajout d’un nouveau protocole nécessite de le faire reconnaître par les serveurs. Un serveur web classique devrait pouvoir répondre assez facilement à ce genre de requêtes. Mais il faut aussi modifier les logiciels clients actuels, si tant est que l’on souhaite se baser sur les logiciels clients existants.
Requêtes/réponses
…
Comportement au téléchargement d’objets
Comportement global (téléchargement sans localisation précisée) :
- Si l’empreinte de l’objet demandé est 0, on quitte le processus de téléchargement.
- Si l’objet existe déjà dans le répertoire public des objets, on quitte le processus de téléchargement.
- Si l’objet existe déjà dans le répertoire privé des objets, on quitte le processus de téléchargement.
- Si l’objet n’a pas de lien dans le répertoire public des liens, on quitte le processus de téléchargement.
- Si l’objet n’a pas de lien dans le répertoire privé des liens, on quitte le processus de téléchargement.
- On se réfère à l’objet
0f183d69e06108ac3791eb4fe5bf38beec824db0a2d9966caffcfef5bc563355(« nebule/objet/entite/localisation ») pour trouver la localisation de toutes les entités connues. - On parcourt les différentes localisations une à une (cf comportement local) pour essayer de télécharger l’objet demandé jusqu’à en obtenir une copie valide si c’est possible.
Comportement local (téléchargement sur une localisation précise) :
- Si l’empreinte de l’objet demandé est 0, on quitte le processus de téléchargement.
- Si l’objet existe déjà dans le répertoire public des objets, on quitte le processus de téléchargement.
- Si l’objet existe déjà dans le répertoire privé des objets, on quitte le processus de téléchargement.
- Si l’objet n’a pas de lien dans le répertoire public des liens, on quitte le processus de téléchargement.
- Si l’objet n’a pas de lien dans le répertoire privé des liens, on quitte le processus de téléchargement.
- On télécharge un objet sur une localisation précise vers le répertoire public des objets.
- Si il est vide, on supprime l’objet.
- Si l’empreinte est invalide, on supprime l’objet.
Comportement au téléchargement de liens
…
Cryptographie sur les liens
Le chiffrement permet de dissimuler des liens. Il est optionnel.
Cryptographie sur les objets
Le chiffrement permet de cacher le contenu des objets. Il est optionnel.
Ce chiffrement doit être résistant, c’est à dire correspondre à l’état de l’art en cryptographie appliquée. On doit être en mesure de parfaitement distinguer l’objet en clair de l’objet chiffré, même si le second est dérivé du premier.
Deux étapes de chiffrement
Les entités sont des objets contenant le matériel cryptographique nécessaire au chiffrement asymétrique. Cependant, le chiffrement asymétrique est très consommateur en ressources CPU (calcul). On peut l’utiliser directement pour chiffrer les objets avec la clé publique d’un correspondant, mais cela devient rapidement catastrophique en terme de performances et donc en expérience utilisateur. D’un autre côté, le chiffrement symétrique est beaucoup plus performant, mais sa gestion des clés de chiffrement est délicate. Pour améliorer l’ensemble, il faut mixer les deux pour profiter des avantages de chacun.
Ainsi, on va aborder le chiffrement en deux étapes distinctes.
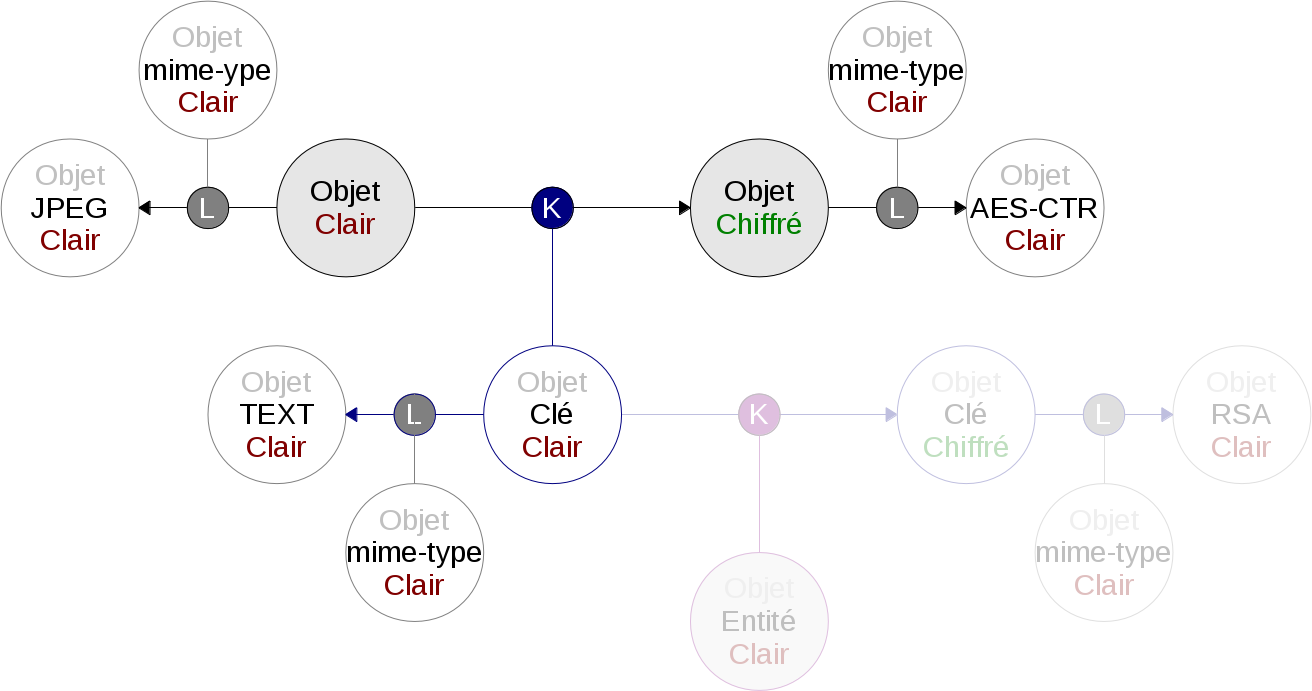
Pour la compréhension des schémas, ne pas oublier que les propriétés des objets sont elles-mêmes des objets…
Étape chiffrement symétrique
Le chiffrement d’un objet peut prendre du temps, surtout si il est volumineux. On va donc privilégier le chiffrement symétrique qui est assez rapide. Nous avons besoin pour ce chiffrement de deux valeurs.
La première valeur est une clé de chiffrement. Elle est dite clé de session. La longueur de celle-ci dépend de l’algorithme de chiffrement utilisé. Par exemple, elle fait 128bits pour l’AES. Elle est générée aléatoirement. C’est cette valeur qui va permettre le déchiffrement de l’objet et doit donc rester secrète. Mais il faut pouvoir la partager avec ses correspondants, c’est ce que l’on verra dans la deuxième étape.
La seconde valeur est ce que l’on appelle une semence ou vecteur initial (IV = Initial Vector). Elle est utilisée dans la méthode de chiffrement sur plusieurs blocs, c’est à dire lorsque l’on chiffre un objet dont la taille dépasse le bloc, quantité de données que traite l’algorithme de chiffrement. Par exemple, le bloc fait 128bits pour l’AES, tout ce qui fait plus que cette taille doit être traité en plusieurs fois. Comme IV, je propose d’utiliser l’identifiant de l’objet à chiffrer, c’est à dire le hash de cet objet. Cela simplifie la diffusion de cette valeur qui n’a pas à être dissimulée.
L’objet source que l’on voulait à l’origine protéger peut maintenant être marqué à supprimer. Il pourra être restauré depuis l’objet dérivé chiffré et la clé de session.
Sur le schéma ci-dessous, la partie chiffrement symétrique est mise en valeur. On retrouve l’objet source en clair qui est ici une image de type JPEG. En chiffrant cet objet, cela génère un nouvel objet. Le chiffrement est matérialisé par un lien de type K. Ce lien associe aussi un objet contenant la clé de session. Le nouvel objet est de type AES-CTR, par exemple. Cela signifie qu’il est chiffré avec le protocole AES et la gestion des blocs CTR (CounTeR). L’objet contenant la clé de session est de type texte.
Étape chiffrement asymétrique
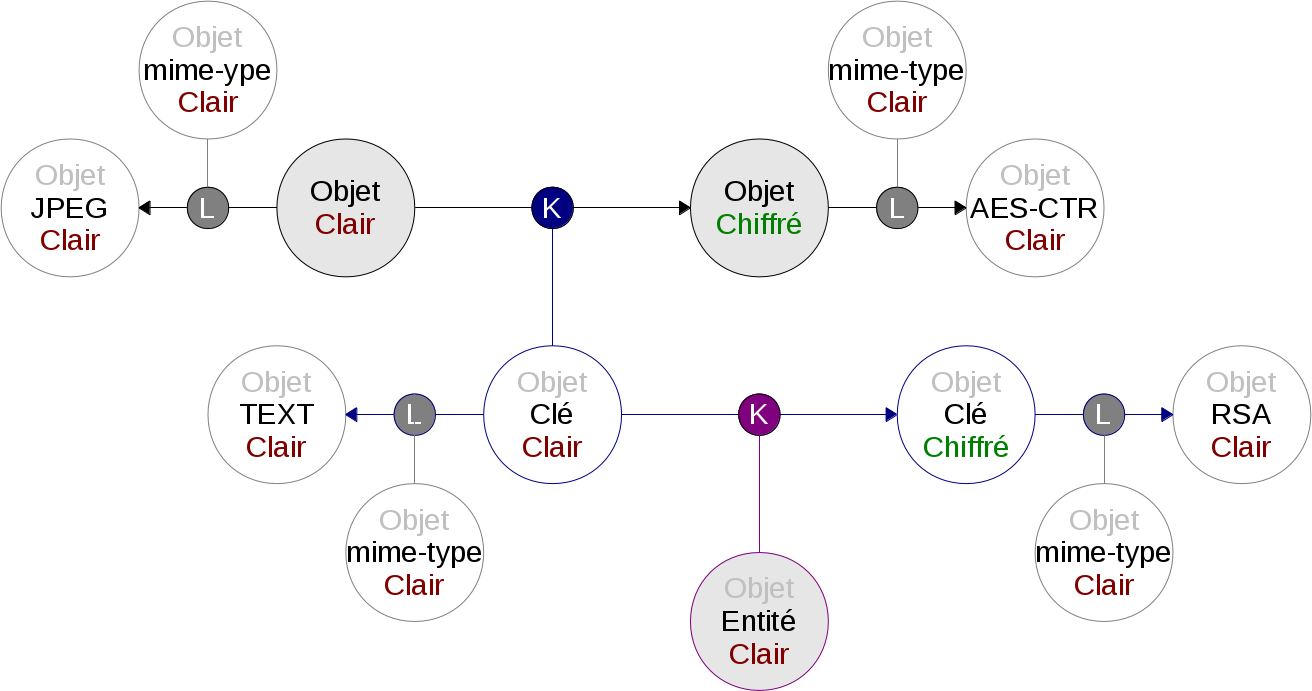
Suite à la première étape de chiffrement, nous nous retrouvons avec un objet chiffré et un objet contenant la clé de session. Si le fichier chiffré est bien protégé (en principe) et peut donc être rendu public, l’objet avec la clé de session est au contraire bien embarrassant. C’est là qu’intervient le chiffrement asymétrique et les clés publiques/privées.
Le système de clés publiques/privées va permettre de chiffrer l’objet contenant la clé de session avec la clé publique d’une entité. Ainsi on permet à cette entité, c’est à dire le destinataire, de récupérer la clé de session avec sa clé privé et donc de lire l’objet source. Et plus encore, en re-chiffrant cette même clé de session avec d’autres clés publiques, ce qui génère autant d’objets de clés chiffrés, nous permettons à autant de nouvelles entités de lire l’objet source.
Le créateur de l’objet chiffré doit obligatoirement faire partie des entités destinataires si il souhaite pouvoir déchiffrer l’objet source plus tard. Sinon, il passe intégralement sous le contrôle d’une des entités destinataires.
Sur le schéma ci-dessous, la partie chiffrement asymétrique est mise en valeur. On retrouve l’objet en clair qui est ici la clé des session. En chiffrant cet objet, cela génère un nouvel objet. Le chiffrement est matérialisé par un lien de type K. Ce lien associe aussi un objet contenant la clé publique d’une entité. Le nouvel objet est de type RSA.

Ensemble du processus de chiffrement
Évidemment, ce schéma de chiffrement ne ré-invente pas la roue. C’est une façon de faire assez commune, voire un cas d’école. Mais il est ici adapté au fonctionnement particulier de nebule et de ses objets.
Il y a deux points à vérifier : – Partager l’objet chiffré et permettre à une autre entité de le voir, c’est aussi lui donner accès à la clé de session. Rien n’empêche cette entité de rediffuser ensuite cette clé de session en clair ou re-chiffrée à d’autres entités. Cependant, la clé de session est unique et n’a pas de valeur en dehors de l’objet chiffré qu’elle protège. De même, l’objet source peut toujours être re-chiffré avec une nouvelle clé de session et d’autres clés publiques. On retombe sur un problème commun, insoluble et le même constat : on perd automatiquement le contrôle de toute information que l’on diffuse à autrui. – L’empreinte (hash) de la clé de session est publique. Peut-être que cela affaiblie le chiffrement et donc la solidité de la protection des objets. A voir…
Par commodité, je pense qu’il serait intéressant de lier explicitement l’entité destinataire et l’objet chiffré.
Voici le schéma de l’ensemble :
Chiffrement et vecteur initial
Pour la plupart des modes de chiffrements symétriques, un vecteur initial (semence ou IV) est nécessaire. Il est lié à l’objet chiffré pour permettre le déchiffrement de celui-ci. Par défaut, sa valeur est aléatoire.
Si pas précisé, il est égale à 0.
Du fait du fonctionnement du mode CTR (CounTeR), l’IV s’incrémente à chaque bloc chiffré.
Chiffrement et compression
Il est préférable d’associer de la compression avec le chiffrement.
La compression des données déjà chiffrées est impossible, non que l’on ne puisse le faire, mais le gain de compression sera nul. L’entropie détermine la limite théorique maximum vers laquelle un algorithme de compression sans pertes peut espérer compresser des données. Quelque soit l’entropie des données d’origine, une fois chiffrées leur entropie est maximale. Si un algorithme obtient une compression des données chiffrées, il faut sérieusement remettre en question la fiabilité de l’algorithme de chiffrement. CF Wikipedia – Entropie de Shannon.
A cause de l’entropie après chiffrement, si on veut compresser les données il est donc nécessaire de le faire avant le chiffrement.
Ensuite, il faut choisir l’algorithme de compression. On pourrait forcer par défaut cet algorithme, pour tout le monde. C’est notamment ce qui se passe pour le HTML5 avec le WebM ou le H.264… et c’est précisément ce qui pose problème. En dehors des problèmes de droits d’utilisation à s’acquitter, c’est une facilité pour l’implémentation de cette compression par défaut dans les programmes. Cela évite de devoir négocier préalablement l’algorithme de compression. Mais si il est difficile de présenter des vidéos en plusieurs formats à pré-négocier, ce n’est pas le cas de la plupart des données. On perd la capacité d’évolution que l’on a en acceptant de nouveaux algorithmes de compression. Et plus encore, on perd la capacité du choix de l’algorithme le plus adapté aux données à compresser. Il faut donc permettre l’utilisation de différents algorithmes de compression.
Cependant, si l’objet à chiffrer est déjà compressé en interne, comme le PNG ou OGG par exemple, la compression avant chiffrement est inutile. Ce serait une sur compression qui bien souvent n’apporte rien. Le chiffrement n’implique donc pas automatiquement une compression.
Lors du chiffrement, l’objet résultant chiffré est lié à l’objet source non chiffré par un lien k. Il est aussi marqué comme étant un objet de type-mime correspondant à l’algorithme de chiffrement, via un lien l. Pour marquer la compression avant chiffrement, un autre lien l est ajouté comme type-mime vers l’algorithme de compression utilisé. Ce lien n’est ajouté que dans le cas d’une compression réalisée en même temps que le chiffrement.
La seule contrainte, c’est l’obligation d’utiliser un algorithme de compression sans perte. L’objet, une fois décompressé doit être vérifiable par sa signature. Il doit donc être strictement identique, aucune modification ou perte n’est tolérée.
Chiffrement et type mime
Il n’existe pas de type mime généralistes pour des fichiers chiffrés. Comme les objets chiffrés ne sont liés à aucune application en particulier.
Il faut aussi un moyen de préciser l’algorithme de chiffrement derrière. Une application aura besoin de connaître cet algorithme pour déchiffrer le flux d’octets. En suivant la rfc2046, il reste la possibilité de créer quelque chose en application/x-...
Voici donc comment seront définis les objets chiffrés dans nebule :
application/x-encrypted/aes-256-ctrapplication/x-encrypted/aes-256-cbcapplication/x-encrypted/rsa
Etc…
En fonction de l’algorithme invoqué, on sait si c’est du chiffrement symétrique ou asymétrique, et donc en principe si c’est pour une clé de session ou pas.
Résolution de conflits
Comment se comporter face à un objet que l’on sait (lien k) chiffré dans un autre objet mais qui est disponible chez d’autres entités ? Si on est destinataire légitime de cet objet, on ne le propage pas en clair. On ne télécharge pas la version en clair. On garde la version chiffrée.