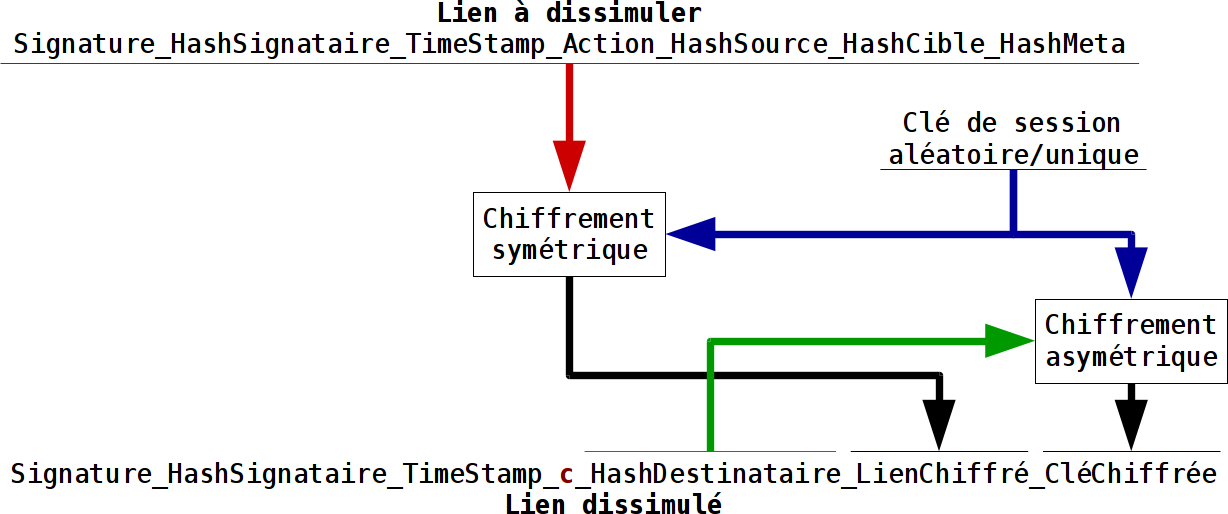
La dissimulation de lien tel que prévu dans nebule n’est que la première partie permettant l’anonymisation des échanges entre entités.
Voir les articles précédents :
– Liaison secrète et suite ;
– Nouvelle version v1.2, Anonymisation de lien et correction du registre ;
– Lien de type c, précisions ;
– Entités multiples, gestion, relations et anonymat et Entité multiples ;
– Nébuleuse sociétale et confiance – Chiffrement par défaut
Cette dissimulation d’un lien se fait avec un lien de type c. On a bien sür dans le registre du lien visible l’entité qui génère ce lien, l’entité signataire. Et on a l’entité destinataire qui peut déchiffrer ce lien dissimulé et en extraire le vrai lien. Et comme dans la version publique de ce lien on a à la fois l’entité source et l’entité destinataire qui sont visibles, il n’y a pas d’anonymat. Ce type de lien permet juste de dissimuler l’usage d’un objet.
Un lien dissimulé ne peut pas contenir un autre lien dissimulé. On interdit donc les multi-niveaux de liens dissimulés qui seraient un véritable calvaire à traiter.
Un lien peut être dissimulé pour soi-même. C’est à dire que l’entité signataire est aussi l’entité destinataire.
Si un lien doit être dissimulé pour plusieurs destinataires, il faut générer un lien pour chaque destinataire. La seule façon de réduire le nombre de liens pour un grand nombre de destinataires est d’utiliser la notion de groupe disposant de son propre bi-clé. Ce type de groupe est pour l’instant purement théorique.
Ce maintien comme public des entités sources et destinataires est une nécessité au niveau du lien, c’est une des bases de la confiance dans les liens. Pour que le lien puisse être validé et accepté par une entité ou retransmit par un relais, l’identification des entités est incontournable. Et donc avec l’identification nous avons aussi l’imputabilité et la non répudiation.
Si on veut assurer de l’anonymat pour les entités, puisque l’on ne peut pas travailler au niveau du lien, il faut travailler au niveau de l’entitié. On va dans ce cas travailler sur la notion de déception, c’est à dire faire apparaître des entités pour ce qu’elles ne sont pas ou tromper sur la nature des entités.
L’idée retenu consiste, pour chaque entité qui souhaite anonymiser ses échanges avec une autre entité, à générer une entité esclave avec laquelle elle n’a aucun lien. Ou plutôt, le lien d’entité maîtresse à entité esclave est un lien dissimulé pour l’entité maîtresse uniquement. Ici, personne à par l’entité maîtresse ne peut affirmer juste sur les liens que l’entité esclave lui est reliée.
Lorsque l’on veut échanger de façon anonyme, on transmet à l’entité destinataire l’identifiant de l’entité esclave, et vice versa. Cette transmission doit bien sür être faîte par un autre moyen de communication ou au pire par un seul lien dissimulé.
L’anonymisation complète est donc la combinaison des liens de dissimulation de liens et d’une capacité multi-entités des programmes.
La dissimulation est en cours d’implémentation dans sylabe en programmation php orienté objet. Mais le plus gros du travail sera à faire dans la librairie nebule puisque c’est elle qui manipulera les liens et présentera ceux-ci à l’application, c’est à dire sylabe, dans une forme exploitable. L’application n’a pas à se soucier de savoir si le lien est dissimulé, elle peut le lire ou elle ne peut pas. Tout au plus peut-elle afficher qu’un lien est dissimulé pour information de l’utilisateur.
La capacité multi-entités de sylabe est maintenant beaucoup plus facile à gérer en programmation php orienté objet. Mais il reste à implémenter la génération des entités esclaves avec dissimulation de leur entité maîtresse.
Une autre dimension n’est pas prise en compte ici, c’est le trafic entre les serveurs pour les échanges d’informations. Il faudra faire attention à la remontée possible aux entités maîtresses par leurs échanges.
Enfin, pour terminer, aujourd’hui c’est la course au chiffrement par défaut de tous les échanges pour tout un tas de programmes et services sur Internet. Ce chiffrement par défaut est bon pour l’utilisateur en général. Et il masque dans la masse les échanges pour qui la confidentialité est critique. Ainsi il ne suffit plus d’écouter le trafic chiffré pour retrouver ses ennemis.
Mais cette logique est perverse. Le chiffrement par défaut est une aberration, un remède de cheval posé en urgence faut de mieux. Nous avons besoin d’échanger aussi des choses publiquement, comme sur un forum ou dans la presse. Nous ne devrions pas avoir des outils de communication tout chiffré et d’autres tout public, chaque outil devrait permettre les deux et clairement indiqué ce qui est protégé de ce qui ne l’est pas…