L’entité bachue existe depuis un certain temps en tant que telle. Mais il est difficile de diffuser dans de bonnes conditions les objets et liens qu’elle signe. De bonnes conditions sont ici à interpréter comme conditions de sécurité et facilité d’exploitation.
Cette entité est matérialisée par une clé RSA en deux parties, une publique et une privée. La clé privée doit être manipulée avec précaution dans un environnement strictement contrôlé. La perte ou la divulgation de la clé privée remettrait en question tout ce qui a été diffusée par cette entité, surtout si c’est du code. En terme de sensibilité, elle est en troisième position derrière puppetmaster et cerberus.
Les technologies employées actuellement ont toutes des vulnérabilités en ligne à certains moments. Si ces vulnérabilités peuvent être comblées, il n’en demeure pas moins une petite période de temps pendant lequel elles deviennent à la fois publiques et non encore comblées. Le problème est pire encore avec les vulnérabilités non publiques (0-days) contre lesquelles une machine unique ne peut pas avoir de défense efficace. Donc la machine qui héberge l’entité bachue, la machine hôte, ne peut être laissée connectée sur un réseau externe.
Tout ce qui est manipulé par nebule supporte sans aucun problème les transferts via le réseau ou via des supports amovibles et est manipulable sur des systèmes d’exploitations différents. Il est aisé de travailler avec des stations non connectées et de diffuser simplement l’information via des relais en ligne même plus faiblement protégés.
Chaque machine à un rôle strictement définit avec des règles de gestion en conséquences. Toutes les machines ne sont pas installées avec le même système d’exploitation et toutes les machines ne reposent pas sur la même architecture matériel. Des machines tournent notamment avec un processeur SUN SPARC ou un processeur PowerPC en plus des classiques processeurs Intel/AMD 32bits ou 64bits. Microsoft Windows a été écarté pour sa forte présomption (impossible à démontrer ou à réfuter) de compromission par des entités étatiques.
Voici le schéma de principe retenu actuellement pour la gestion des objets et liens par bachue :
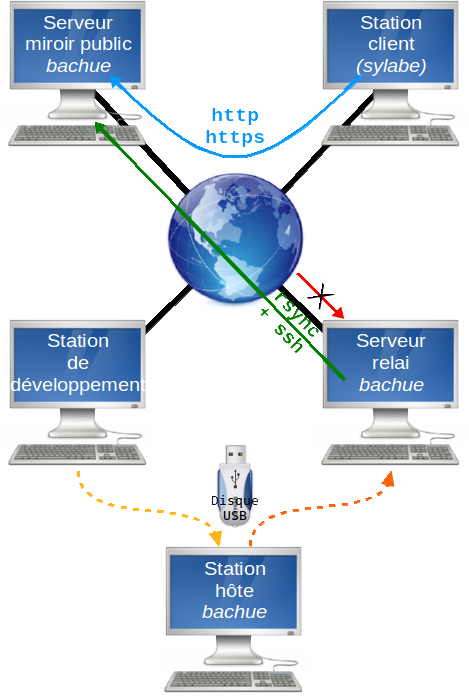
1 – La station de développement est unique mais pourra s’étendre à plusieurs machines. C’est une machine assez classique et qui sert à bien d’autres choses que nebule. C’est actuellement le principal point de faiblesse, le principal point d’entrée d’une attaque.
1->2 – Depuis la station de développement, on exporte les liens et objets associés sur une clé USB vers la station hôte bachue.
2 – La station hôte est la seule et unique machine sur laquelle sera déverrouillée l’entité bachue. C’est la machine la plus critique du dispositif. Les seuls vecteurs d’attaque sont la clé USB et un accès physique frauduleux.
Toutes les clés USB insérées sont systématiquement nettoyées. Le nettoyage consiste en la suppression de tout fichier autre que le fichier ‘l’ ou ce qu’il y a dans le dossier ‘o’. Le fichier ‘l’ ne doit contenir que des caractères imprimables. Le dossier ‘o’ ne doit pas contenir de sous dossiers. Les fichiers du dossier ‘o’ doivent avoir une empreinte valide.
Si les liens sont ceux attendus, ils sont signés par l’entité.
Cette station ne se met pas à jour régulièrement des correctifs de sécurité. Ce processus est réalisé à la main si nécessaire. La machine est préparée pour résister aux deux vecteurs d’attaques connus.
2->3 – Les nouveaux liens sont exportés par la même clé USB vers le serveur relais.
3 – Le serveur relais contient une copie de ce que l’entité bachue partage publiquement. Il n’est pas très critique puisqu’une compromission serait facilement détectée dans les liens et objets. La suppression de certains objets ou liens serait facilement réparable. Ce serveur est protégé derrière un pare-feu qui bloque toute tentative de connexion depuis Internet vers le serveur ainsi que toute connexion non référencée depuis le serveur vers Internet.
Toutes les clés USB insérées sont systématiquement nettoyées. Le nettoyage consiste en la suppression de tout fichier autre que le fichier ‘l’ ou ce qu’il y a dans le dossier ‘o’. Le fichier ‘l’ ne doit contenir que des caractères imprimables. Les liens dans le fichier ‘l’ doivent être de bachue uniquement et leurs signatures sont vérifiées. Le dossier ‘o’ ne doit pas contenir de sous dossiers. Les fichiers du dossier ‘o’ doivent avoir une empreinte valide.
Ce serveur se tient automatiquement à jour de correctifs de sécurité directement sur Internet.
Les nouveaux objets sont ajoutés aux objets déjà présents. Les nouveaux liens sont insérés dans les fichiers de liens via la librairie nebule.
3->4 – L’ensemble des objets et liens sont synchronisés vers le serveur miroir public avec rsync encapsulé dans ssh.
4 – Le serveur miroir est un serveur web disponible en permanence sur Internet. Il n’est pas critique dans sont contenu puisque toutes modifications des objets ou liens seront immédiatement rejetées par les autres entités. Il n’est que peut critique en terme de disponibilité puisque les objets et liens peuvent être diffusés par d’autres entités. Il n’est pas critique non plus en terme de sensibilité des données qu’il partage puisque toutes les données sont soit librement publiables soit chiffrées.
Ce serveur se tient automatiquement à jour de correctifs de sécurité directement sur Internet.
4->5 – Chaque entité peut venir consulter les liens et objets sur le serveur miroir public.
5 – La station cliente est autonome. Elle gère ses propres processus et assure sa propre protection.