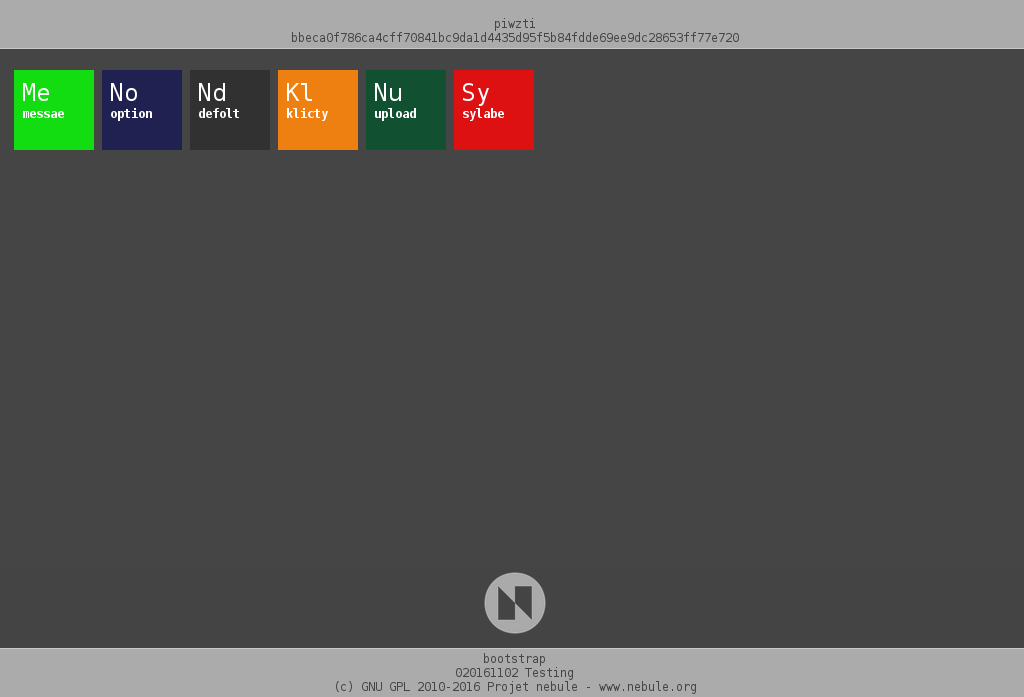
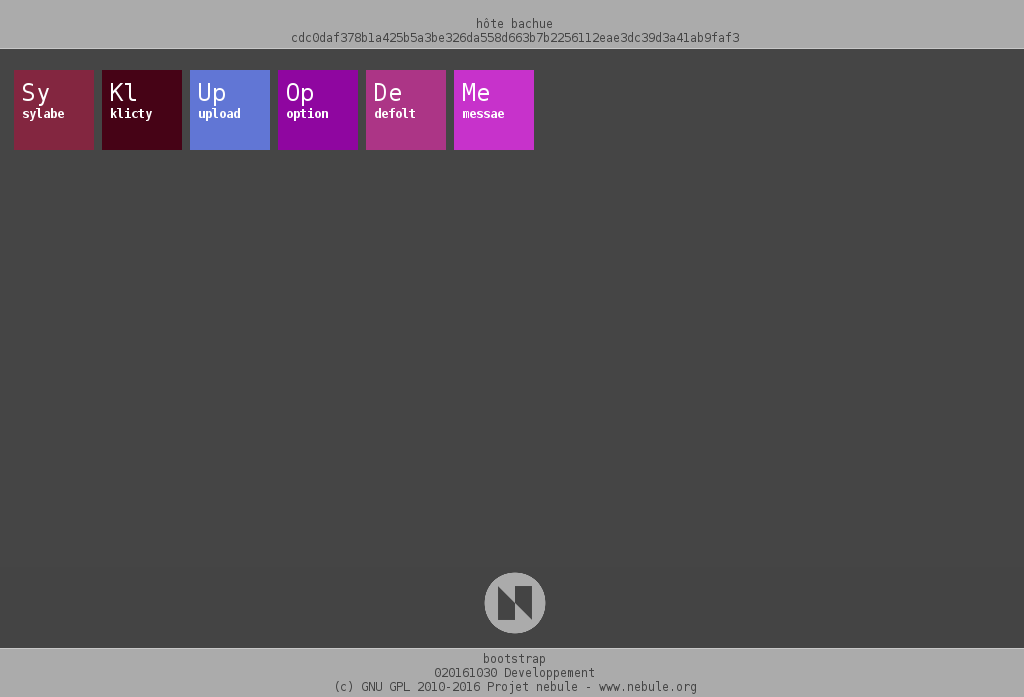
Le bootstrap sait maintenant gérer les applications activées. Ça se passe à deux niveaux.
- L’application 0 de sélection des applications n’affiche que les applications activées.
- Le moteur de sélection de l’application à afficher ne permet pas de sélectionner une application si elle n’est pas activée.
L’activation d’une application se fait sur trois critères :
- C’est l’application par défaut définit par l’option
defaultApplication, elle est par défaut activée et non désactivable. - C’est une des applications en liste blanche. La liste blanche est une constante définie dans le bootstrap et dans la bibliothèque. Elleet non désactivable.
- L’entité instance du serveur a activé explicitement l’application par un lien.
L’entité maître du code bachue ne peut pas activer une application sauf à modifier les constantes dans le code.
Une application peut être activée/désactivée via l’application option, la seule application aujourd’hui en liste blanche. Il faut aller dans la partie des applications et il faut être connecté avec l’instance entité du serveur.

Le lien d’activation d’une application a la forme :
- action :
f - source : objet de référence de l’application, par exemple =
e5ce3e9938247402722233e4698cda4adb44bb2e01aa0687 - cible : objet de référence d’activation =
e0e9ce893ea87b91f6e276b3839fed99f050168a0eb986354adc63abb3d7335c - méta : objet de référence de l’application, par exemple =
e5ce3e9938247402722233e4698cda4adb44bb2e01aa0687
La désactivation est un lien de type x.