Suite à l’article Anonymisation/dissimulation des liens – ségrégation et temporalité et ségrégation partielle, la réflexion et l’implémentation sur le stockage et l’échange des liens dissimulés progresse.
La méthode de ségrégation des liens dissimulés développée est suffisante pour retrouver les liens dissimulés et les partager. Mais si le partage est efficace parce que l’on ne récupère que les liens dissimulés des entités connues, la lecture des liens n’est clairement pas efficace.
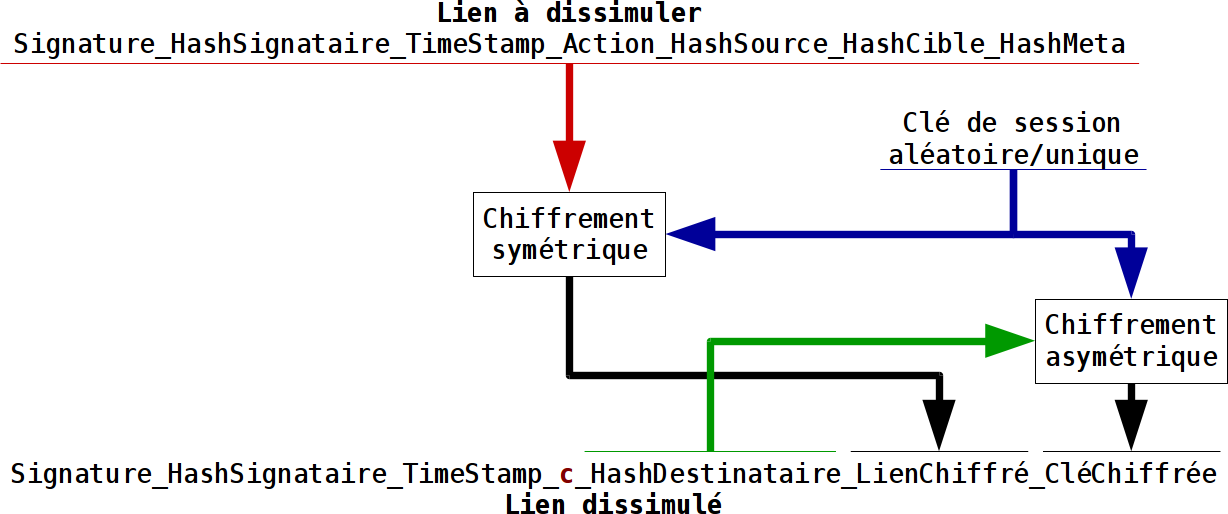
Lors de la consultation des liens d’une objet particulier, il faut lire tous les liens de l’objet, facile, et lire l’intégralité des liens dissimulés parce que l’on ne sait pas à l’avance quelle entité à dissimulé des liens pour cet objet. Il manque de pouvoir localement (indépendamment du partage) stocker les liens en fonction des objets source, cible et méta. Mais il faut aussi ne pas dévoiler cette association d’objets cités dans la partie dissimulée du lien, ce qui permet rapidement de lever la partie dissimulée.
Il est possible de transcoder les identifiants des objets cités par le lien dissimulé. On parle bien de travailler toujours sur des fichiers de stockage dédiés aux liens dissimulés, et donc indépendamment des liens non dissimulés. Ce transcodage doit permettre de ne pas révéler l’association entre les objets cités par le lien dissimulé. Ce transcodage peut être commun à tous les objets avec une clé de codage commune, ou chaque objet peut disposer de sa propre clé de codage. Et bien sür, chaque entité dispose de sa/ses clés de transcodage, donc chiffrées avec la clé privée.
Un transcodage avec une clé unique est plus facile puisque l’on peut chiffrer cette clé et la stocker à un endroit unique, mais il est moins sür que le transcodage à clés individuelles.
Pour commencer on va partir sur la base de la clé unique de transcodage.
Les liens dissimulés dans des fichiers transcodés sont lisibles publiquement et peuvent potentiellement être synchronisés mais ils n’ont pas vocation à remplacer les liens dissimulés dans les fichiers dédiés à la ségrégation et utilisés lors du partage des liens.
Le nettoyage des fichiers des liens dissimulés et transcodés devient un nouveau problème.
Plusieurs entités pouvant localement générer des liens dissimulés, et donc utiliser des clés de transcodage différentes, il n’y a pas de méthode de nettoyage générique des liens dissimulés dans les fichiers transcodés. Seule une entité peut faire le nettoyage de ses propres fichiers transcodés. Il faut donc que ces fichiers transcodés soient clairement associés à une entité.
Il est possible par contre de supprimer tous les fichiers transcodés d’une entité (ou plus). Il faut dans ce cas que l’entité, une fois déverrouillée, reconstitue ses fichiers transcodés.
Cela lève un nouveau problème, comment savoir que tous les fichiers transcodés sont présents et qu’ils sont à jour. Avec cette méthode, il ne faut pas que les fichiers dédiés à la ségrégation des liens dissimulés pour une entité soient manipulés par une autre entité parce que les fichiers transcodés ne seront pas synchrones. Et les transferts ne sont pas possibles.
Les entités ne doivent pas synchroniser les liens dissimulés des autres entités !
Il reste encore des réflexions à mener autour de cette méthode de transcodage.