Au fil du temps l’interface graphique, communément appelée Interface Homme-Machine (IHM), implémentée dans les dérivés de nebule s’améliore et se structure autour de la bibliothèque commune. Cette bibliothèque incorpore de mieux en mieux la préparation de plus en plus d’éléments graphiques communs.
Cependant elle reste insatisfaisante.
Il n’est pas question de parler d’un interface d’application qui apporterait quelques solutions à certains problèmes mais entraînerait de fait bien des problèmes d’interopérabilité et le suivi des codes qui vont avec.
L’interface web semble la plus adaptée aujourd’hui mais traîne malgré sa bonne standardisation la question de la gestion des multiples supports d’affichages. La philosophie habituelle à la mode consiste à faire gérer par même page l’ensemble des affichages possibles dans tout le gradient entre les plus minuscules smartphones et les ordinateurs aux écrans très haute résolution. Sans parler du très faible écart en résolution des écrans à mettre en parallèle à leur l’écart de tailles.
C’est sans compter aussi le questionnement sur l’usage invasif et disproportionné du JavaScript (JS). De plus en plus de pages web sur Internet incorporent des parties de code/JS/images/etc venant de différents CDN. L’éclatement du moteur de la page en de multiples dépendances est tenable avec l’Internet actuel mais est profondément en opposition au fonctionnement de nebule et est par nature très sensible à la fragmentation possible de l’Internet dans le futur. Le JS trop pointu est clairement une source de dysfonctionnement ainsi qu’une source de problèmes de sécurité.
L’interface comporte deux parties:
- le contenu de la page contenant l’information principale attendue par l’utilisateur ;
- le cadre de la page avec des informations liées à l’environnement de l’information affichée ou à l’application.
Ces deux parties doivent être plus clairement décorrélées graphiquement. L’idée est d’essayer de rendre plus léger, aérien, le contenu et plus discret le cadre.
La vision d’avenir, sauf catastrophe, ce sont d’un côté des écrans toujours plus grands avec des résolutions toujours plus fines. Quand on dit grand c’est vraiment grand, au point que de vouloir mettre en plein écran une application n’ai plus vraiment de sens. Et d’un autre côté une scission des appareils nomades en de multiples composants plus ou moins autonomes parmi lesquels l’écran sera détaché au plus près des yeux de l’utilisateur, là encore avec des résolutions très fortes et avec de la transparence (canal alpha). Il faut aussi voir disparaître le clavier et la souris au profit du tactile, de la commande vocale et du pilotage par les yeux et même via une interface avec le cerveau. Il faut penser dès maintenant à préparer l’affichage des pages pour qu’il y ai une continuité entre la page web affichée aujourd’hui et celle affichée avec les évolutions prévisibles de demain.
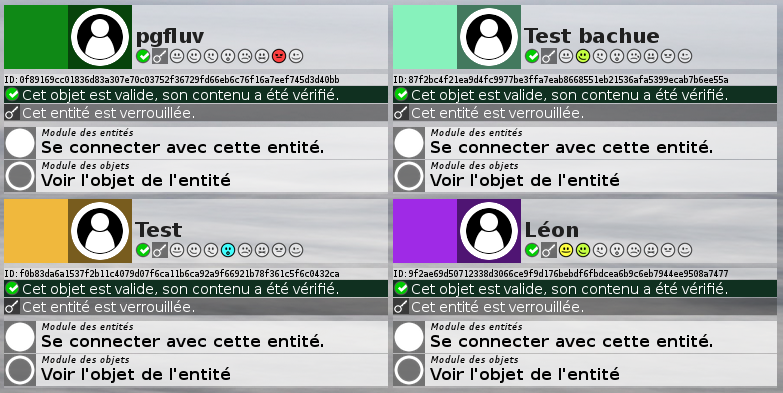
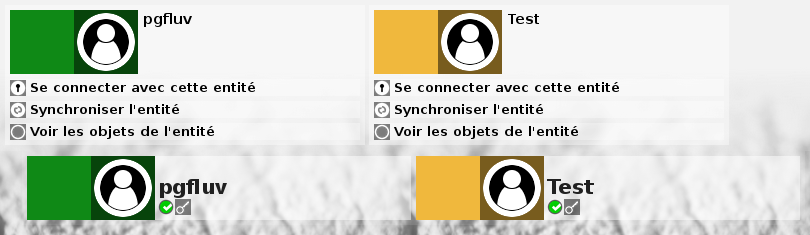
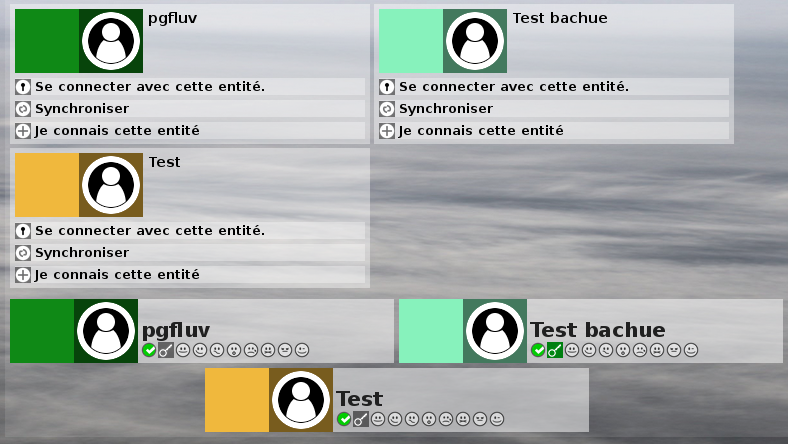
La présence quasi systématique du double carré d’un objet peut permettre de le rendre actif en y cachant un menu des actions possibles simplement en cliquant dessus. Ainsi une liste d’objet ne sera plus polluée par de multiples boutons dans le cadre et sous chaque objets. Le menu lié à l’objet est bien sür contextuel dans l’application et dépendant du type d’objet. Dans la page qui affiche les entités, cliquer sur une entité fera afficher le menu lui correspondant dans lequel on trouvera le bouton qui permet de se connecter avec cette entité.
Dans les menus du cadre ou des objets, l’activation d’un bouton ne sera plus immédiatement suivi d’une action, et d’un rechargement de page, mais fera apparaître des informations plus précises sur l’action du bouton et demandera un déplacement explicite sur un nouveau bouton pour valider l’action. Ainsi ce fonctionnement n’est pas trop pénalisant pour un usage à la souris et est très adapté à l’usage mobile tactile sur de petits écrans.
Les messages qui s’affichent en début de contenu, typiquement des alertes, seront systématiquement affichés à chaque rechargement d’une page mais devront pourvoir être cachés pour mieux accéder au contenu.
L’affichage du contenu doit être centré par défaut horizontalement et verticalement. Sur un écran de petite résolution on doit limiter l’affichage pour avoir juste ascenseur vertical. Sur un écran de haute résolution le cadre sera suffisamment loin pour que tout ce que l’on fait sur l’objet en cours d’affichage soit clairement une action sur l’objet. On peut à l’avenir imaginer que l’espace du contenu dispose de plusieurs zones qui affichent des objets différents simultanément, et donc potentiellement dans des contextes différents.
Le cadre doit contenir les informations sur l’entité connectée et le contenu doit faire référence au besoin à la vue restreinte à une entité si ce n’est pas l’entité connectée.