Dans sylabe, la mise en place de la traduction sous forme de modules a apporté son lot de problèmes de sécurité. Les modules peuvent contenir tout un tas de code qui ne sont pas en rapport avec la traduction. Il faut interdire par tous les moyens l’ajout de code malveillant inconnu. Il est très difficile de filtrer finement ces codes pour ne garder au mieux que ce qui concerne les traduction ou au pire rejeter l’objet qui le contient. La solution retenu est de ne reconnaître que les modules signés soit par bachue, soit par l’entité locale.
Les fonctions _l_grx et _l_gr1 de la librairie en php prennent maintenant en compte un paramètre pour restreindre la recherche des liens de mise à jours (résolution du graphe des mises à jours) aux deux entités citées ci-dessus.
Mais, si fonctionnellement c’est suffisant, on va maintenant plus loin. Au lieu de ne reconnaître que deux entités, il est maintenant possible d’en ajouter plus de façon statique. On crée en quelque sorte une liste d’autorités locales. Cette liste n’est valable que sur un serveur et pour une seule instance de sylabe ou tout autre programme similaire.
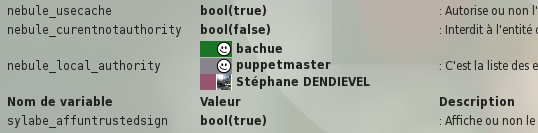
Ainsi, la variable $nebule_local_authority contient une liste des entités faisant office d’autorité locale. Elle est pré-remplie par défaut avec l’entité bachue. Elle peut être complétée.
Une autre variable $nebule_curentnotauthority permet d’interdire à l’entité courante d’être elle aussi autorité locale. A false par défaut, l’entité locale peut ajouter des modules. C’est notamment pratique pour le développement puisque l’on peut faire soi-même des évolutions de ces modules. A true, l’entité locale ne peut qu’utiliser les modules par défaut présents localement.
Il est bien sür possible de positionner ces deux variables dans les fichiers de configuration env_nebule.php et env_sylabe.php. Cependant, leur comportement est un tout petit peu différent dans le bootstrap et dans la librairie (via une application comme sylabe).
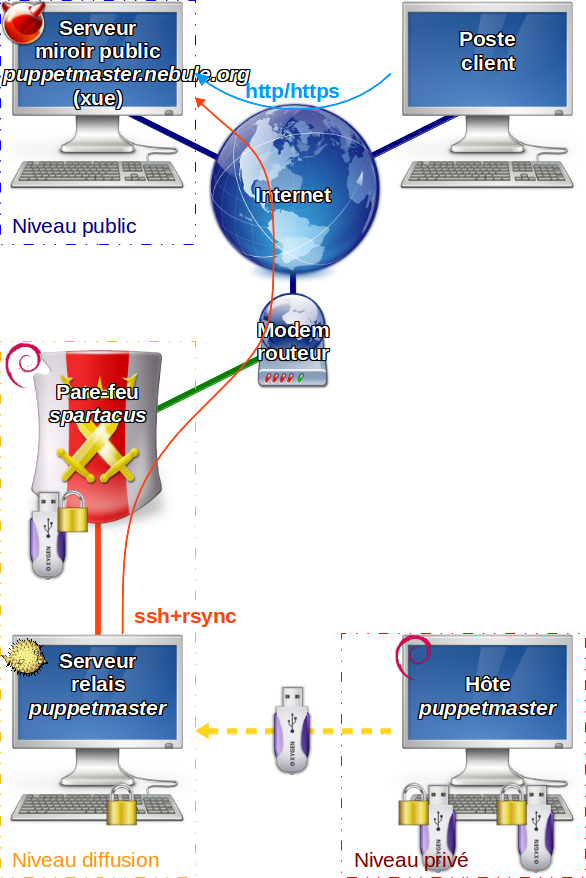
Quelques explications s’imposent pour comprendre les différences. Schéma de fonctionnement global d’une instance :
1 – Appel du bootstrap (index.php) par le serveur web.
V
2 – Exécution du script php.
3 – Lecture du fichier de configuration env_nebule.php.
4 – Recherche de la librairie nebule valide à charger.
5 – Chargement de la librairie nebule (fonctions et variables).
6 – Recherche de l’application par défaut et valide.
(actuellement, c’est sylabe)
7 – Le bootstrap charge l’application et passe la main.
V
8 – Exécution du script php de l’application.
9 – Lecture du fichier de configuration env_sylabe.php.
10 – Déroulement du script de l’application…
Lors de l’exécution du bootstrap, celui-ci n’utilise pas la session utilisateur gérée par php. Il va cherche si le fichier e existe et si c’est une entité. Il prend cette entité comme étant l’entité propriétaire de l’instance. Si avec la variable $nebule_curentnotauthority on empêche de reconnaître cette entité comme autorité, seule bachue sera autorité et donc seuls ses mises à jours seront prises en compte. Ainsi, il n’est pas possible pour l’entité locale de modifier la librairie ou le programme (sylabe) sauf si ils sont signés par bachue. Une mise à jour régulière est possible.
Lors de l’exécution de l’application, ici sylabe, l’entité locale n’est pas forcément l’entité courante. Et l’entité courante n’est donc pas forcément propriétaire de l’instance mais juste utilisatrice. Si avec la variable $nebule_curentnotauthority on empêche de reconnaître cette entité comme autorité, seule bachue sera autorité et donc seuls ses modules seront pris en compte. Ainsi, il n’est pas possible pour l’entité courante de modifier les modules. Une mise à jour régulière est possible.
En clair, l’entité locale choisit la librairie nebule et le programme à charger, l’entité courante dans le programme choisit les modules. Si cela ne leur est pas interdit.
Pour ajouter d’autres autorités, il suffit de les ajouter à la variable $nebule_local_authority dans les fichiers de configuration :
$nebule_local_authority[]='88848d09edc416e443ce1491753c75d75d7d8790c1253becf9a2191ac369f4ea';