Suite à l’intégration des groupes dans la librairie php, l’ensemble est fonctionnel et stable dans la librairie ainsi que dans klicty.
Catégorie : Implémentation
Intégration des groupes dans la librairie php
Suite à la définition des groupes, l’intégration a commencé dans la librairie php orienté objet.
L’intégration est profonde puisque les groupes sont gérés comme des objets spécifiques comme c’était déjà le cas pour les entités. Une classe dédiée ainsi que tout un tas de fonctions leurs sont dédiés et personnalisés.
Les applications sylabe et klicty vont intégrer progressivement les groupes, notamment dans un module adapté.
Dans le même temps, un groupe fermé étant uniquement constitué de liens d’une seule entité (et cela doit être vérifié), le filtre social est en cours de mise en place. Ainsi, il est possible de restreindre la prise en compte des liens suivant ces filtres sociaux :
- self : liens de l’entité ;
- strict : liens de l’entité et des entités autorités locales ;
- all : toutes les entités, mais avec un classement par pondération des entités.
L’activation du filtre social et donc de la possibilité de le choisir dans le code à nécessité un revue de tout le code de la librairie et des applications. Il reste à vérifier les modules de sylabe.
Liens de propriétés d’un objet
Rien de vraiment nouveau pour ce début d’année 2016.
Via la librairie php, on pouvait récupérer une ou des propriétés d’un objet avec le contenu de ces propriétés, on peut maintenant récupérer juste le ou les liens correspondants. Ainsi il est possible d’extraire facilement d’autres informations sur ces propriétés comme la date ou l’entité créatrice…
Intégration d’une partie affichage dans la librairie PHP
Des corrections de buggs sont réalisés dans la librairie nebule en PHP ainsi que dans le bootstrap en fonction des progrès de klicty.
Pour faciliter le développement et la cohérence de l’affichage, la librairie nebule en PHP intègre maintenant une partie ‘display‘ dédiée à l’affichage de petites parties de pages comme par exemple un objet. La gestion globale de l’affichage reste du ressort des applications comme sylabe ou klicty.
Historique des liens générés
Il y avait dans la librairie nebule en php procédural une option permettant de copier au moment de leur écriture les nouveaux liens générés. C’est une forme d’historique qui vient en complément de la possibilité d’écriture des nouveaux liens signés dans les liens de l’entité signataire. Par défaut tout arrivait dans le fichier l/f qu’il fallait bien sür penser à vider de temps en temps.
Mais cela n’avait pas été ré-implémenté. C’est maintenant fait dans la librairie en php orienté objet. L’option permitHistoryLinksSign permet d’activer cette fonctionnalité et est par défaut à false, soit désactivé.
C’est utile pour le développement puisqu’il suffit de récupérer les derniers liens des programmes en cours de développement pour les faire signer par une autorité de code (bachue). C’est plus facile que d’aller faire la pêche aux liens sur les différents objets concernés.
Projet klicty
Voici donc venir le projet klicty. C’est un dérivé de sylabe mais en plus spécialisé et donc plus léger aussi. En attendant qu’il ai sont propre blog, voici donc quelques captures. Globalement, il va permettre le partage de fichiers sur Internet, mais bien sür le moteur c’est nebule…
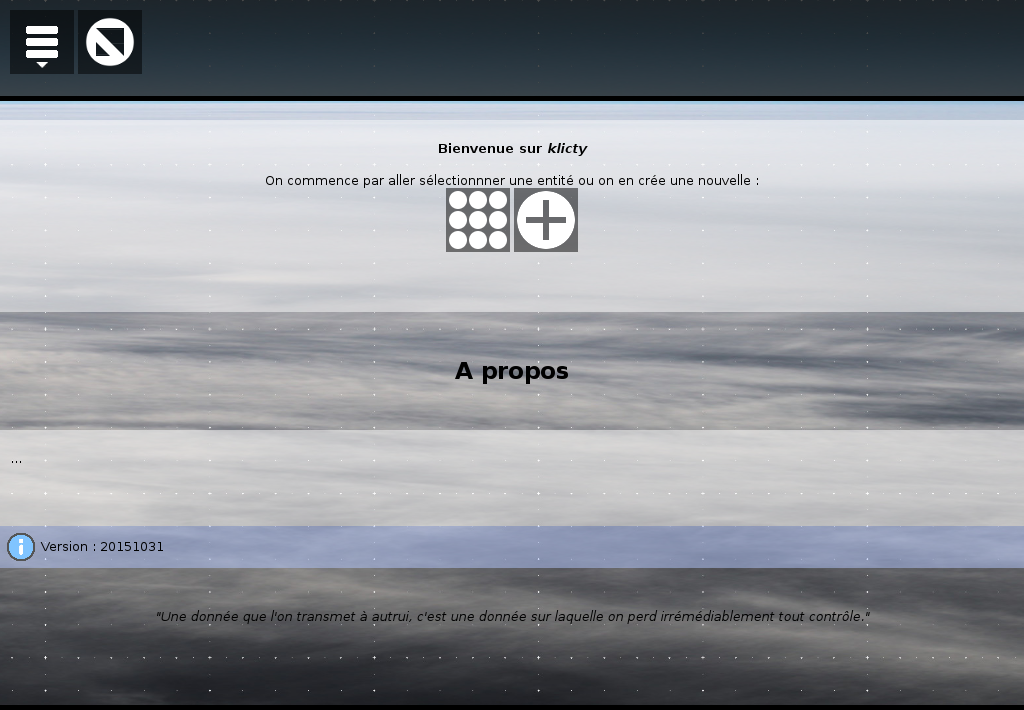 Écran d’accueil.
Écran d’accueil.
Page par défaut du bootstrap
Le bootstrap évolue un peu dans la présentation de sa page par défaut :
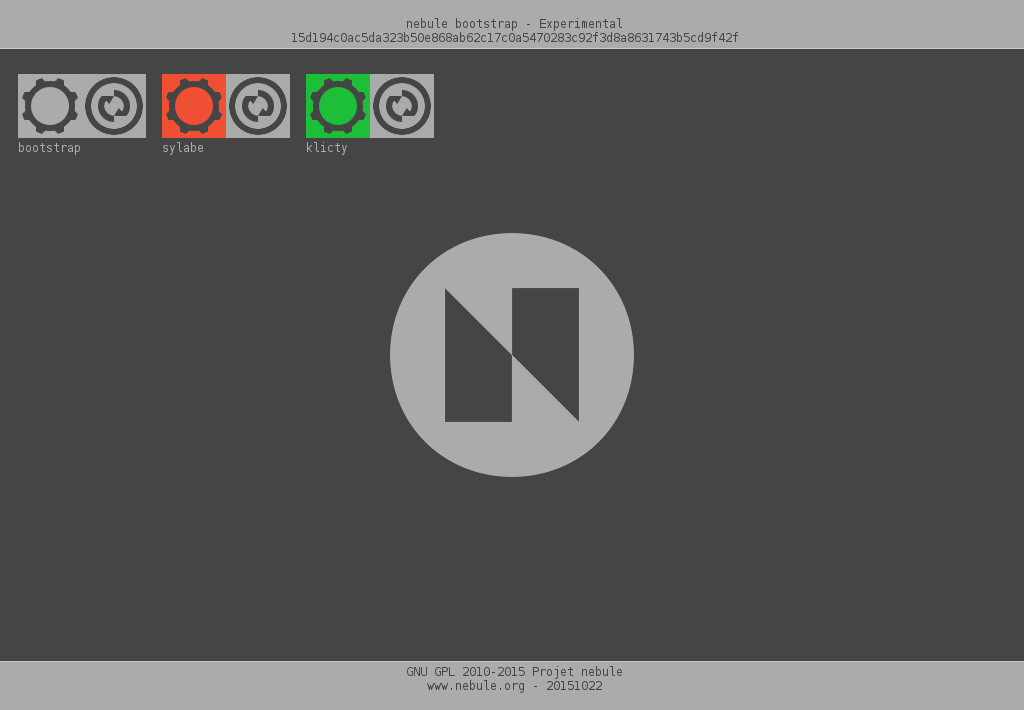
Une nouvelle application klicty s’ajoute à sylabe, c’est pour plus tard…
Mais sur un serveur, il n’y aura sürement qu’une seule application, et elle sera utilisée par défaut plutôt que de passer par cette page du bootstrap.
Gestion des applications au niveau du bootstrap
Le bootstrap était jusque là assez sommaire. Il se contentait de trouver la dernière version valide de l’application en cours puis la chargeait pour affichage à l’utilisateur. Une page spécifique permettait, et permet toujours, de voir les caractéristiques du bootstrap et de son travail à des fins de dépannage, mais sans interaction possible.
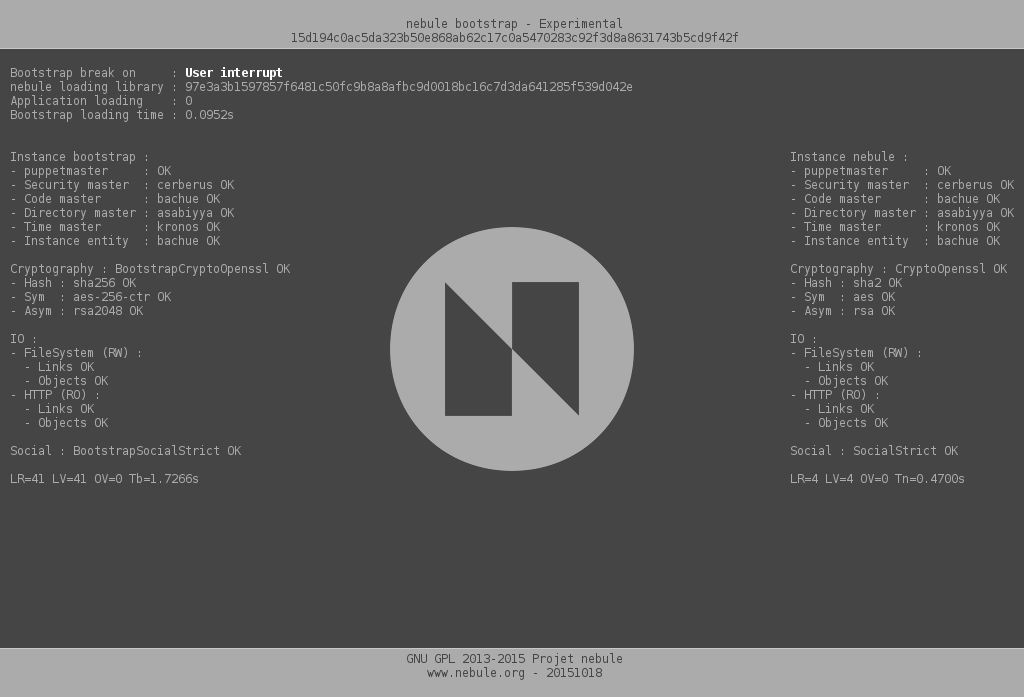
La page de dépannage du bootstrap. Continuer la lecture de Gestion des applications au niveau du bootstrap
Permettre les modifications par défaut – annulation
Certaines options avaient été modifiées dans le bootstrap et la librairie. Voir l’article Permettre les modifications par défaut.
Ces modifications étaient nécessaires pour que le bootstrap puisse générer ou télécharger les objets et liens manquants à la mise en place de son environnement. Maintenant, lors du premier lancement, un fichier d’options par défaut est mise en place avec les options d’écritures nécessaires, puis ce fichier est remplacé à la fin avec des options verrouillées par défaut.
C’est plus propre comme ça.
Auto-installation depuis le bootstrap
Le bootstrap est en cours de modification pour pouvoir être posé tout seul sur un nouveau serveur. Il crée dans ce cas l’environnement nécessaire à son fonctionnement et télécharge ce qui manque.
Le but est ici de simplifier au maximum l’installation. Il restera ensuite à changer l’application par défaut, mais c’est un autre problème…
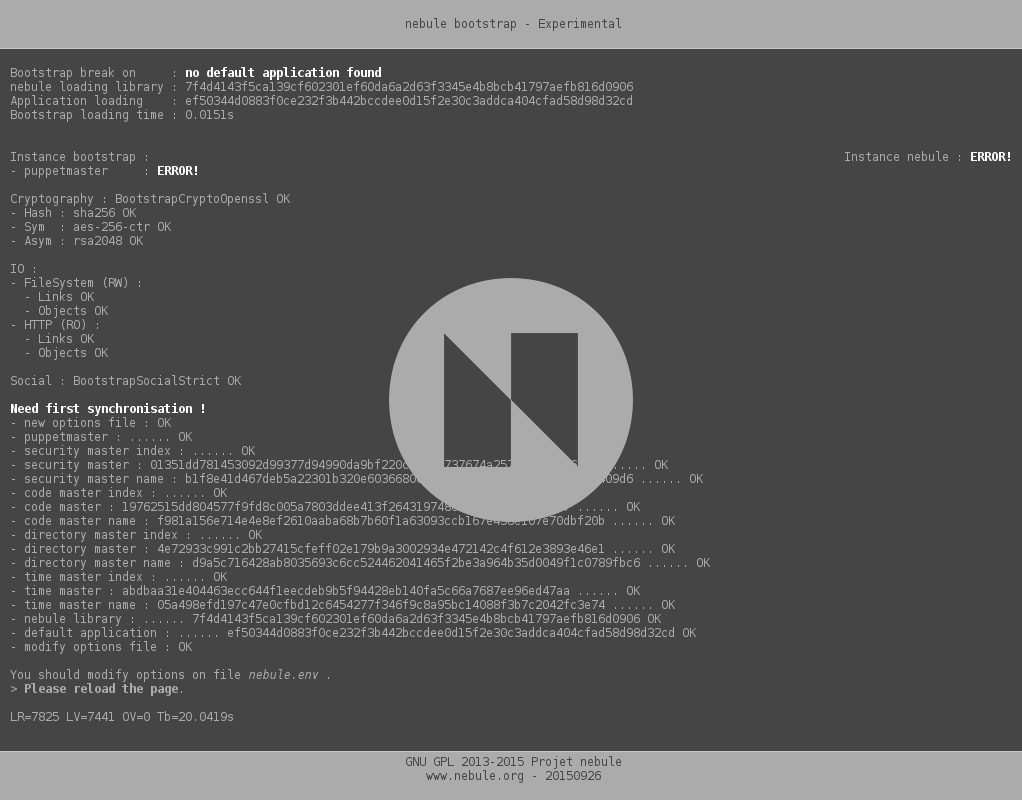
Le bootstrap en cours de création de son environnement de travail.
Il reste à faire la partie qui génère une nouvelle entité pour l’instance locale. Par défaut c’est le puppetmaster, mais il n’y a pas de raison que ce soit lui partout. Avec la génération de cette entité, il sera affiché le mot de passe pour que son propriétaire puisse se l’approprier.
Permettre les modifications par défaut
La modification du bootstrap est en cours pour la préparation par défaut d’un nouvel environnement sur un serveur vierge.
Cependant, les options permitWrite, permitWriteObject et permitWriteLinks étaient par défaut à false. Et comme sur un nouveau serveur il n’y a pas de fichier contenant les options, c’était false la réponse par défaut pour ces options. Cela induit que la librairie refuse par défaut d’écrire les objets et liens associés pour la création du nouvel environnement et donc l’impossibilité de préparer ce nouveau serveur…
Ces options sont maintenant à true par défaut.
Objet réservé pour les pseudo systèmes de fichiers
Pour les besoins de sylabe et la gestion des équivalents de systèmes de fichiers, un objet réservé à été créé : nebule/arborescence
Il sert de repère pour les points d’entrés des arborescences des systèmes de fichiers. C’est ajouté au wiki Documentation – nebule v1.2 – Objets à usage réservé.
Liens marqués entre le puppetmaster et les autres entités
Il y a quelques jours, le puppetmaster a été réveillé pour générer de nouveaux liens. De nouveaux objets de nebule sont maintenant reconnus comme des objets à usage réservé :
nebule/objet/entite/maitre/securitenebule/objet/entite/maitre/codenebule/objet/entite/maitre/annuairenebule/objet/entite/maitre/temps
Et il permettent de désigner via un lien de type f les différentes entités qui ont les rôles correspondants.
Le code de la librairie nebule en php et le bootstrap s’en servent désormais pour retrouver les entités avec ces rôles.
CF : sylabe – Avancement
Dissimulation de liens, multi-entités et anonymat
La dissimulation de lien tel que prévu dans nebule n’est que la première partie permettant l’anonymisation des échanges entre entités.
Voir les articles précédents :
– Liaison secrète et suite ;
– Nouvelle version v1.2, Anonymisation de lien et correction du registre ;
– Lien de type c, précisions ;
– Entités multiples, gestion, relations et anonymat et Entité multiples ;
– Nébuleuse sociétale et confiance – Chiffrement par défaut
Cette dissimulation d’un lien se fait avec un lien de type c. On a bien sür dans le registre du lien visible l’entité qui génère ce lien, l’entité signataire. Et on a l’entité destinataire qui peut déchiffrer ce lien dissimulé et en extraire le vrai lien. Et comme dans la version publique de ce lien on a à la fois l’entité source et l’entité destinataire qui sont visibles, il n’y a pas d’anonymat. Ce type de lien permet juste de dissimuler l’usage d’un objet.
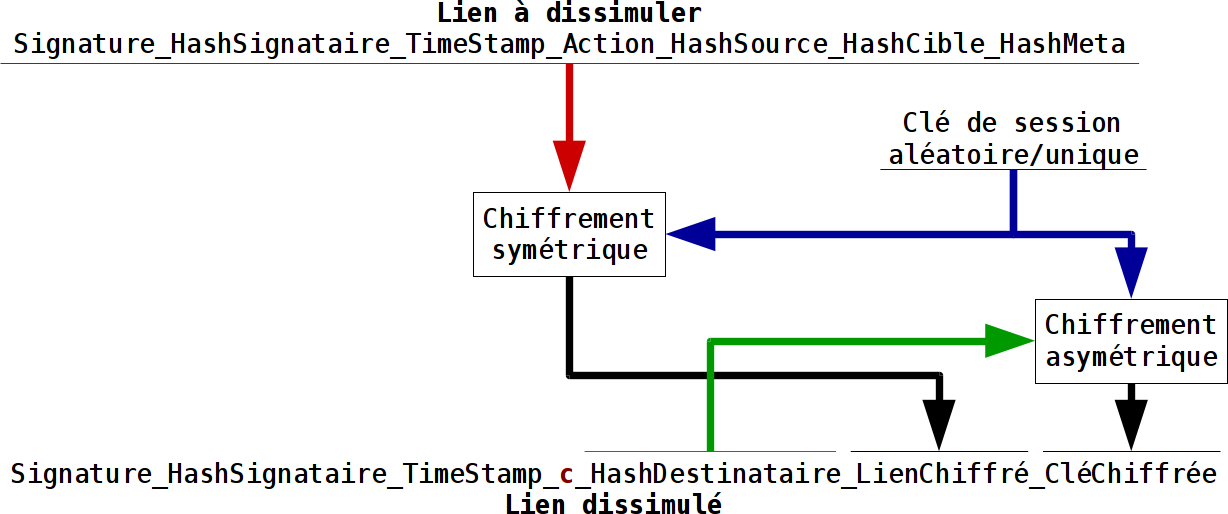
Un lien dissimulé ne peut pas contenir un autre lien dissimulé. On interdit donc les multi-niveaux de liens dissimulés qui seraient un véritable calvaire à traiter.
Un lien peut être dissimulé pour soi-même. C’est à dire que l’entité signataire est aussi l’entité destinataire.
Si un lien doit être dissimulé pour plusieurs destinataires, il faut générer un lien pour chaque destinataire. La seule façon de réduire le nombre de liens pour un grand nombre de destinataires est d’utiliser la notion de groupe disposant de son propre bi-clé. Ce type de groupe est pour l’instant purement théorique.
Ce maintien comme public des entités sources et destinataires est une nécessité au niveau du lien, c’est une des bases de la confiance dans les liens. Pour que le lien puisse être validé et accepté par une entité ou retransmit par un relais, l’identification des entités est incontournable. Et donc avec l’identification nous avons aussi l’imputabilité et la non répudiation.
Si on veut assurer de l’anonymat pour les entités, puisque l’on ne peut pas travailler au niveau du lien, il faut travailler au niveau de l’entitié. On va dans ce cas travailler sur la notion de déception, c’est à dire faire apparaître des entités pour ce qu’elles ne sont pas ou tromper sur la nature des entités.
L’idée retenu consiste, pour chaque entité qui souhaite anonymiser ses échanges avec une autre entité, à générer une entité esclave avec laquelle elle n’a aucun lien. Ou plutôt, le lien d’entité maîtresse à entité esclave est un lien dissimulé pour l’entité maîtresse uniquement. Ici, personne à par l’entité maîtresse ne peut affirmer juste sur les liens que l’entité esclave lui est reliée.
Lorsque l’on veut échanger de façon anonyme, on transmet à l’entité destinataire l’identifiant de l’entité esclave, et vice versa. Cette transmission doit bien sür être faîte par un autre moyen de communication ou au pire par un seul lien dissimulé.
L’anonymisation complète est donc la combinaison des liens de dissimulation de liens et d’une capacité multi-entités des programmes.
La dissimulation est en cours d’implémentation dans sylabe en programmation php orienté objet. Mais le plus gros du travail sera à faire dans la librairie nebule puisque c’est elle qui manipulera les liens et présentera ceux-ci à l’application, c’est à dire sylabe, dans une forme exploitable. L’application n’a pas à se soucier de savoir si le lien est dissimulé, elle peut le lire ou elle ne peut pas. Tout au plus peut-elle afficher qu’un lien est dissimulé pour information de l’utilisateur.
La capacité multi-entités de sylabe est maintenant beaucoup plus facile à gérer en programmation php orienté objet. Mais il reste à implémenter la génération des entités esclaves avec dissimulation de leur entité maîtresse.
Une autre dimension n’est pas prise en compte ici, c’est le trafic entre les serveurs pour les échanges d’informations. Il faudra faire attention à la remontée possible aux entités maîtresses par leurs échanges.
Enfin, pour terminer, aujourd’hui c’est la course au chiffrement par défaut de tous les échanges pour tout un tas de programmes et services sur Internet. Ce chiffrement par défaut est bon pour l’utilisateur en général. Et il masque dans la masse les échanges pour qui la confidentialité est critique. Ainsi il ne suffit plus d’écouter le trafic chiffré pour retrouver ses ennemis.
Mais cette logique est perverse. Le chiffrement par défaut est une aberration, un remède de cheval posé en urgence faut de mieux. Nous avons besoin d’échanger aussi des choses publiquement, comme sur un forum ou dans la presse. Nous ne devrions pas avoir des outils de communication tout chiffré et d’autres tout public, chaque outil devrait permettre les deux et clairement indiqué ce qui est protégé de ce qui ne l’est pas…
Description de la création d’une nouvelle entité.
La ré-implémentation de la génération d’une nouvelle entité est en cours dans sylabe.
Une nouvelle partie apparaît dans la documentation de référence sur la création d’une entité : Wiki – Documentation nebule v1.2 – Création d’une entité
On y trouve la procédure de référence à implémenter et notamment tout ce qui concerne la manipulation des clés cryptographiques asymétriques et mots de passes.
Gestion locale et globale des paramètres
Pour l’instant, les paramètres de configuration de nebule et de sylabe se font via un fichier de configuration sur le serveur.
Il sera possible plus tard de permettre la configuration de certains paramètres de façon globale, c’est à dire via un objet dédié.
Tous les paramètres ne pourront pas être globaux, à définir.
Comme d’habitude, le contenu pourra être public et/ou privé.
On peut déjà prévoir qu’un paramètre public sera mal défini et surchargé par le même paramètre mais privé. C’est une forme de défense par déception.
Authentification et mot de passe
Dans la version précédente, procédurale, de la librairie nebule en php, l’authentification était gérée via des variables de la session. On retrouvait l’ID de l’entité en cours ainsi que l’ID de la clé privée associée et le mot de passe (si déverrouillé) de cette clé privée.
Les anciennes variables :
– $_SESSION['nebule_publ_entite']
– $_SESSION['nebule_priv_entite']
– $_SESSION['nebule_pass_entite']
Dans la nouvelle version de la librairie, en programmation orientée objet, la première variable qui référence l’entité en cours d’utilisation est toujours nécessaire.
Par contre, la variable qui référence la clé privée est encore utilisé mais n’est déjà plus vraiment indispensable puisque l’instance (l’objet au sens programmation) de l’entité contient la référence à l’ID de sa clé privée. Cet ID de clé privée est pré-calculée lors de l’initialisation de l’instance et est accessible par une fonction publique. Il est même possible que cette variable de session pour la clé privée disparaisse à terme faute d’usage.
Enfin, la variable contenant le mot de passe de la clé privée, elle, disparaît définitivement. Elle n’était renseignées que lorsque l’entité était déverrouillées. Désormès, le mot de passe, lorsque fourni, est stocké dans l’instance de l’entité en cours. Cette instance référence ainsi la clé privée et le mot de passe associé. Ce mot de passe est bien sür vérifié lors de son enregistrement puisque c’est la seule et unique condition pour considérer l’entité comme déverrouillée, que le mot de passe soit valide sur la clé privée.
En terme de sécurité du code, c’est plus propre. Le mot de passe ne peut être consulté directement par un module malveillant comme avec une variable de session par essence globale et donc accessible partout. Cependant, le mécanisme n’est pas parfait puisqu’une lecture brute de l’instance permet d’en extraire le contenu… et donc le mot de passe. Il faudra trouver un mécanisme pour renforcer ça…
L’usage d’un sel pour le mot de passe est en cours de réflexion sachant qu’il faudra dans ce cas créer un lien pour le rendre publique. C’est un renforcement de la sécurité du mot de passe mais potentiellement une source de panne.
En terme de gestion des entités, c’est plus facile si on change vers une entité que l’on maîtrise puisque les mots de passe des entités esclaves sont accessibles et peuvent être pré-injectés dans les entités correspondantes. Et puis en cas de bascule vers une de ces entités esclaves, le retour à l’entité maîtresse est plus facile aussi puisque le mot de passe pourra rester dans celle-ci.
En terme d’évolution, il est déjà prévisible qu’une forme avancée d’un usage multi-entité verra le jour. CF Entités multiples. La pré-initialisation des mots de passes de toutes les entités sous contrôle (entités esclaves) rendra cet usage beaucoup plus facile. Pour rappel, cet usage multi-entité permettra au choix soit d’utiliser une et une seule entité à un instant donné mais de pouvoir immédiatement et facilement changer d’entité, soit d’utiliser simultanément tout ou partie des entités sous contrôle. Dans ce dernier cas, les actions seront par contre faites avec une seule entité pré-definie pour cela.
Voici la structure de la classe Entity :
class Entity extends Object
{
const ENTITY_MAX_SIZE = 16000;
const ENTITY_PASSWORD_SALT_SIZE = 128;
const ENTITY_TYPE = 'application/x-pem-file';
private $_publicKey = '';
private $_privateKeyID;
private $_privateKey = '';
private $_privateKeyPassword;
private $_privateKeyPasswordSalt;
private $_issetPrivateKeyPassword = false;
private $_faceCache = array();
public function __construct(nebule $nebuleInstance, $id);
public function __destruct();
public function __toString();
private function _loadEntity($id);
private function _createNewEntity();
private function _verifyEntity($entity);
public function getType();
public function getKeyType();
public function getPublicKeyID();
public function getPublicKey();
private function _findPublicKey();
public function getPrivateKeyID();
private function _findPrivateKeyID();
private function _findPrivateKey();
public function setPrivateKeyPassword($passwd);
public function unsetPrivateKeyPassword();
public function checkPrivateKeyPassword();
public function changePrivateKeyPassword($newpasswd);
public function getFullName();
public function getLocalisations();
public function getLocalisation();
public function getFaceID($size=400);
}
Avancement
Entités multiples
Dans la suite des réflexions sur Entités multiples, gestion, relations et anonymat, le développement de la librairie nebule en php continue en tenant compte de cette possibilité.
En gérant le mot de passe d’une entité dans l’objet (php) de cette entité, on peut avoir plusieurs entités déverrouillées à un instant donné. Et comme plusieurs entités sont potentiellement déverrouillées, lorsque l’on consulte un objet chiffré, il ne faut plus seulement regarder si l’entité courante est déverrouillée et donc peut le lire, mais il faut regarder dans tous les destinataires si une des entité n’est pas déverrouillée aussi. Une seule suffit pour déchiffrer l’objet et afficher son contenu.
Il faut cependant faire attention à ce que l’entité courante ait bien l’accès à l’objet chiffré avant de permettre son utilisation parce que cela dévoilerait immédiatement le lien de parenté entre les deux entités. Il est imaginable de basculer immédiatement d’entité courante sur une action de ce genre.
Si on souhaite une bascule complète sur une entité esclave sans interférence d’autres entités, il suffit de vider le mot de passe de tous les objets (php) des entités que l’on ne souhaite plus voir. Cela inclut aussi l’ancienne entité courante qui peut avoir été préalablement sauvegardée avec sont mot de passe pour une restauration ultérieure.
Une des applications de cette capacité multi-entité, c’est le cumule d’entité lors d’un Changement d’identifiant d’entité. Il est possible, le temps de migrer les liens, de pouvoir continuer à consulter les objets de l’ancienne entité tout en utilisant la nouvelle entité.