Suite des articles Entité multi-rôles et suite, Nommage d’entité – préfix, Entités multiples, Changement d’identifiant d’entité et Entités multiples, gestion, relations et anonymat.
La segmentation d’une entité en plusieurs entités avec des rôles différents va nécessiter un peu de travail. La notification du rôle dans le préfixe de nommage des entités ne semble pas opportune.
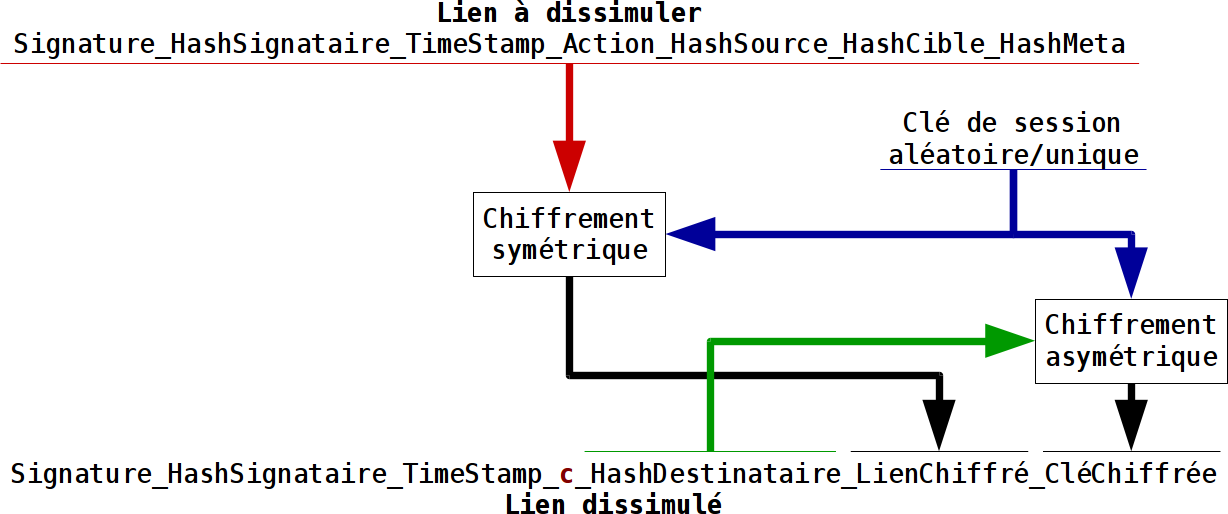
Lors du changement de mot de passe d’une entité, la clé publique ne changeant pas, l’entité reste référencée par le même identifiant, c’est à dire l’empreinte de l’objet de la clé publique. Par contre l’objet de la clé privée va changer, il faut donc un lien pour retrouver cette nouvelle clé privée. Ce n’est pas encore implémenté mais ici rien de compliqué.
Ça va se compliquer avec le problème de diffusion de l’objet de la nouvelle clé privée afin que l’utilisateur puisse l’utilisé pour s’authentifier sur une autre instance serveur. Là on a l’utilité de permettre facilement la synchronisation d’une entité en préalable à une authentification.
Il y a cependant un problème majeure de sécurité des entités. en effet les anciennes clés privées restent toujours présentes et permettent toujours de déverrouille l’entité. Il ne suffit pas de faire une suppression de l’objet concerné, cela n’a que peu de chance de fonctionner face à un attaquant.
Il est possible de générer une nouvelle entité avec sa propre clé publique, ou de tout le cortège d’entités dans le cas du multi-entités. On peut même imaginer ne changer que l’entité d’authentification. Puis on fait des liens pour dire à tout le monde que l’entité a été mise à jour et marquer le lien de parenté. Cela veut malheureusement dire qu’il faut refaire tous les liens avec la nouvelle entité. Peut-être est-ce l’occasion de faire du ménage et oublier des choses…
Quelque soit le mécanisme, il ne protège pas de la compromission d’une entité par un attaquant. Celui-ci peut réaliser une mise à jours de l’entité qui sera vu comme légitime par les autres entités. La récupération de l’entité est possible puisqu’elle existe toujours mais comment vont se comporter les autres entités lorsque l’on va faire une deuxième mise à jours d’entité… en concurrence avec la première. Il y a peut-être un moyen de faire jouer le côté social des relations entre entités et de volontairement créer un challenge entre les deux mises à jours de l’entité et toutes les entités tierces.
Ou alors on accepte la survivance simultané de ces deux entités qui vont progressivement diverger avec le temps. Là aussi un tri social pourra se faire mais plus naturellement.
La solution à ce problème peut être l’usage d’une entité faisant autorité et capable d’imposer une mise à jour d’entité en particulier. Mais on essaie de se débarrasser des autorités encombrantes ce n’est pas pour les réintroduire au premier coup de froid.
Il existe une autre forme d’autorité, ce peut être une entité à soi mais que l’on n’utilise pas au jours le jour et stockée à la maison au chaud. Les cambriolages étant encore un risque contemporain cette entité de recouvrement peut être dupliquée en d’autres lieux. Évidement son vol ne doit pas permettre de prendre le contrôle de l’ensemble.
Il restera toujours le vol sous contrainte. Mais ça on ne peut rien y faire de toute façon.
L’hégémonie d’un mécanisme unique de gestion des identités est un problème puisque une fois ce mécanisme corrompu il n’existe plus de recours pour récupérer son identité.
Ce problème n’a pas vraiment de solution complète et pas encore d’orientation précise pour gérer les conflits. Il reste encore du travail de réflexion…