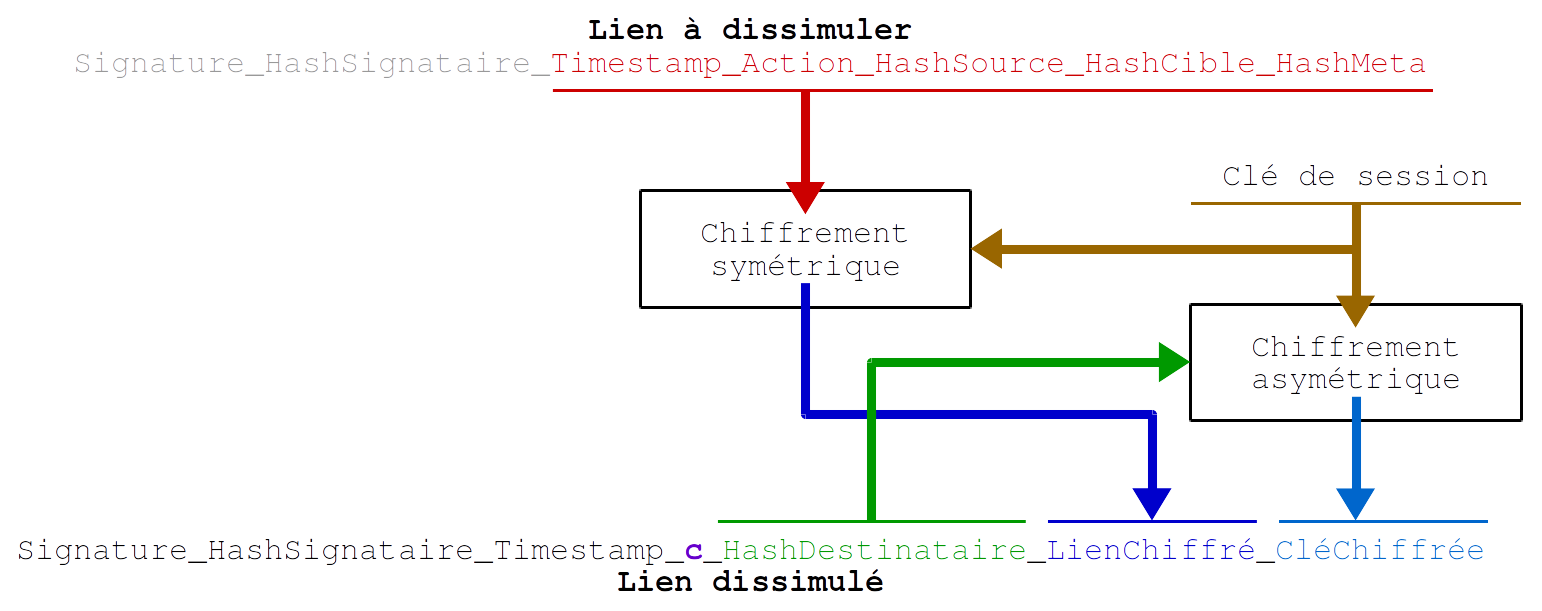
Lorsque un lien est dissimulé, le cÅ“ur du lien à dissimuler est chiffré et placé comme un champs du lien de dissimulation.
Certains liens, en fonction surtout de leur type, peuvent avoir des champs cible et méta à zéro. Ces champs présents mais de valeur nulle ont une taille réduite et calculable. Cela veut dire que la taille du champs du lien dissimulation peut donner une bonne indication non des champs dissimulés mais du champs action du lien à dissimuler, c’est à dire du type de lien.
Cette détermination du type de lien en elle même n’est pas vraiment problématique mais peut être couplée à d’autres informations pour essayer de lever la dissimulation des champs, par exemple un changement de comportement d’une entité signataire ou destinataire du lien de dissimulation. Cependant comme le lien de dissimulation ne doit pas avoir de champs date signifiant, tel que définit dans l’article Schéma lien dissimulé – timestamp, la relation temporelle est difficile à mettre en évidence.
Un problème similaire va se poser avec les liens à dissimuler contenants des identifiants de tailles non conventionnelles, c’est à dire les objets virtuels. La taille résultant ne permet pas retrouver les champs du lien mais donne un indication sur le type d’un des champs.
A cause de la variation de taille non prévisible des champs des liens à dissimuler, il n’est pas possible d’ajouter un bourrage (padding) préventif fixe. Ce bourrage aurait pu simplement des zéros ajoutés au besoin au champs méta sans changer sa signification, ou des caractères espace.
Il est cependant possible d’ajouter un bourrage aléatoire de caractères espace de au moins trois fois la taille du champs source du lien à dissimuler, et de tout au plus cinq fois. Cette fonctionnalité est facile à ajouter lors de la dissimulation d’un lien et ne change ni sa vérification ni son traitement. C’est juste un peu d’espace consommé en plus pour les liens.